Container Elastic Stack para visualização de logs do Proxy Squid
Compartilho neste artigo a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.

Parte 3: Subindo o Elastic Stack
Agora instalaremos as ferramentas que compõem o Elastic Stack.
O Docker permitirá subir um container com Logstash, Elasticsearch e Kibana já integrados e prontos para utilizarmos. Mas, caso você queira instalar manualmente o ambiente, basta consultar os manuais disponíveis no site da Elastic:
Utilizaremos a imagem Docker disponibilizada por Sébastien Pujadas. A imagem possui uma boa documentação, disponível aqui.
Vamos baixar a imagem em questão:
# docker pull sebp/elk
Como requisito do Elasticsearch, para evitar erros de "out of memory" e permitir o armazenamento adequado dos índices, antes de prosseguir verifique na sua distro o valor configurado para o parâmetro "vm.max_map_count":
# sysctl vm.max_map_count
Se o valor for menor do que 262144, altere com o comando:
# sysctl -w vm.max_map_count=262144
Caso queira manter esta alteração após o reboot, insira a configuração no arquivo /etc/sysctl.conf.
Agora, subiremos um container baseado na imagem Docker baixada anteriormente:
# docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
A primeira execução do container é mais demorada devido à configuração inicial dos serviços. O shell no qual você executou o container ficará exibindo os logs do Elastic Stack. O container publicará no localhost às portas 5601/tcp para a interface web do Kibana, 9200/tcp para a interface JSON do Elasticsearch e 5044/tcp para o Logstash receber os logs do Filebeat.
Passos executados para instalação do Beat Filebeat. É importante instalar a versão do Filebeat idêntica à versão utilizada da imagem Docker do Elastic Stack, neste caso a 5.4.0.
Faça download do pacote:
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.4.0-x86_64.rpm
Instale o Filebeat:
# rpm -ivh filebeat-5.4.0-x86_64.rpm
Não inicie o serviço do Filebeat ainda, pois antes temos que configurar o Logstash e o Elasticsearch para receberem adequadamente os logs do Squid.
Com esta configuração, estamos dizendo ao Filebeat para que envie os logs do arquivo /var/log/squid/access.log, do tipo "squid", para o Logstash que está na porta 5044 do host elk. Como padrão do Filebeat, os índices criados no Elasticsearch terão o nome no formato "filebeat-%{+yyyy.MM.dd}" (por exemplo, "filebeat-2015.04.26").
Dois pontos de atenção antes de prosseguir:
Certificado → a imagem Docker utilizada já vem com um certificado pré-configurado para comunicação segura entre o Filebeat e Logstash. Crie o certificado no local configurado no arquivo /etc/filebeat/filebeat.yml, no caso /etc/pki/tls/certs/logstash-beats.crt.
Hostname → ao utilizar este certificado pré-configurado, sua distro deve resolver o nome "elk" para o IP do Logstash, no caso 127.0.0.1 (localhost). Para isso, no arquivo /etc/hosts, adicione ao fim linha que configura os nomes para o IP 127.0.0.1 o nome "elk". Esta linha na minha distro ficou assim:
Caso você queira gerar outro certificado e/ou alterar configurações de segurança, pode seguir as orientações na documentação da imagem Docker.
Agora, criaremos no Elasticsearch o modelo de índice "filebeat", disponibilizado com o Filebeat (/etc/filebeat/filebeat.template.json):
curl -XPUT 'http://elk:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json
Caso o modelo de índice tenha sido criado e enviado com sucesso ao Elasticsearch, você receberá o retorno:
{
"acknowledged" : true
}
Você recorda que o Elasticsearch é baseado em JSON e que o Kibana permite configurar e gerenciar o Elastic Stack? Então, vamos acessar a interface web do Kibana e conferir se o modelo de índice enviado está realmente lá.
Acesse via navegador o endereço http://localhost:5601, visualizando assim a interface web do Kibana que está sendo executado no container Docker. Conforme Figura 3, acesse o menu "Dev Tools", digite o comando "GET _template" na caixa à esquerda do console e clique no botão em forma de "play", conforme destacado na figura. Com isso, o Kibana apresentará na caixa à direita do console o retorno em formato JSON da configuração do modelo de índice.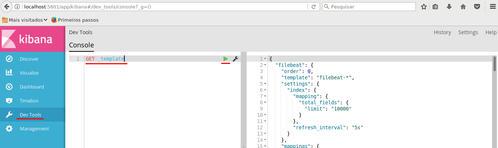
Figura 3 - Consultando modelos de índice no Kibana
Este modelo de índice que acompanha o Filebeat possui alguns types para logs de serviços, como Nginx e Apache. Porém, como não há um type para o Squid, vamos enviar ao Elasticsearch um modelo de índice para configurar o "type" squid e assim armazenar corretamente os "documents" no "index" "filebeat-*".
Para fazer isso, basta colar o conteúdo deste arquivo na caixa à esquerda do console do Kibana e clicar no botão em forma de "play" (Figura 4):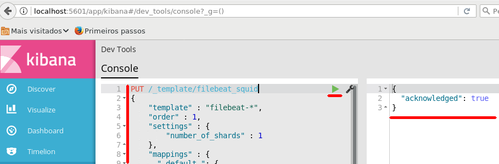
Figura 4 - Aplicando modelo de índice via Kibana
Perceba que, conforme parâmetro "template" acima, este modelo será aplicado sempre que for criado um índice de nome que case com o padrão "filebeat-*". Como já sabemos, o Filebeat por padrão criará índices com o prefixo "filebeat-" no nome.
Também definimos a categoria (type) "squid" com os campos "squid.access.geoip.location" para receber dados do tipo "geo_point" e "squid.access.src_ip" e "squid.access.dst_ip" para receber dados do tipo IP. Os demais campos respeitarão a definição do modelo de índice padrão do Filebeat, ou seja, receberão dados do tipo "keyword".
Agora, para configurarmos o Logstash, você precisará acessar o shell do container Docker. Para isso, execute o comando:
# docker exec -it elk /bin/bash
Acesse o diretório de configuração do Logstash:
# cd /etc/logstash/conf.d
Crie neste diretório o arquivo de configuração "squid.conf", responsável por dizer ao Logstash como tratar os logs do Squid enviados pelo Filebeat. O conteúdo do arquivo deve ser este.
Entendendo o que esta configuração diz ao Logstash: criamos um filtro no qual, caso a mensagem recebida for do tipo "squid" (atributo "document_type" da configuração do Filebeat), utilizamos o plugin "grok" para estruturar o texto das linhas de log do Squid e depois utilizamos o plugin "geoip" para armazenar informações geográficas dos endereços IP acessados pelos clientes do Proxy Squid.
Destaque aqui para o plugin "grok", que é atualmente a melhor forma de o Logstash transformar dados desestruturados (texto) em algo estruturado e rastreável. Este plugin é perfeito para logs como Syslog, Apache, Nginx, MySQL e, em geral, qualquer formato de log geralmente escrito para humanos. Você basicamente utiliza expressões regulares para detectar os dados do texto e estruturá-los.
O Logstash possui cerca de 120 padrões prontos (patterns). Se você precisar de ajuda na construção dos seus próprios patterns, os sites grokdebug.herokuapp e grokconstructor.appspot serão bastante úteis.
Caso queira verificar os detalhes do "grok", veja a documentação oficial.
Para aplicar a nova configuração do Logstash, reinicie o serviço (ainda no shell do container):
# service logstash restart
Com a configuração ok, agora podemos iniciar o serviço do Filebeat:
# systemctl start filebeat.service
Não confunda os shells, pois o Filebeat está instalado no Fedora junto com o Squid, e não no container Docker.
Para que o Squid comece a gerar logs de acesso, você precisa navegar utilizando o proxy. Você pode alterar a configuração de proxy do Firefox (Figura 5) para navegar através do seu Squid: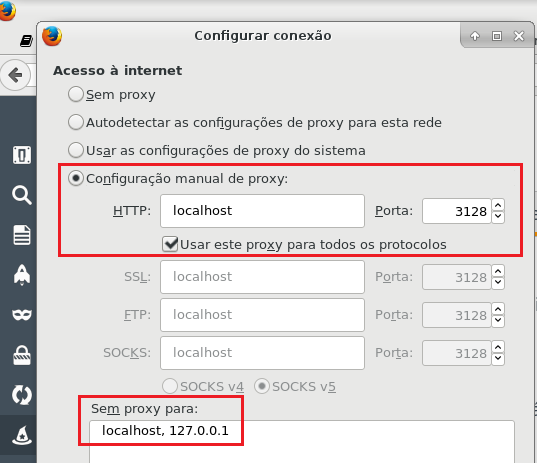
Figura 5 - Configuração de proxy do navegador
A partir do momento em que o Squid começar a gerar logs de acesso, o Filebeat os enviará ao Logstash que por sua vez os normalizará e os enviará ao Elasticsearch. O Elasticsearch criará um novo índice ao receber as informações, com base no template configurado anteriormente.
No momento da criação do índice, você poderá visualizar no log que será exibido no shell do container (Figura 6):
Figura 6 - Índice criado pelo Elasticsearch
O Docker permitirá subir um container com Logstash, Elasticsearch e Kibana já integrados e prontos para utilizarmos. Mas, caso você queira instalar manualmente o ambiente, basta consultar os manuais disponíveis no site da Elastic:
Utilizaremos a imagem Docker disponibilizada por Sébastien Pujadas. A imagem possui uma boa documentação, disponível aqui.
Vamos baixar a imagem em questão:
# docker pull sebp/elk
Como requisito do Elasticsearch, para evitar erros de "out of memory" e permitir o armazenamento adequado dos índices, antes de prosseguir verifique na sua distro o valor configurado para o parâmetro "vm.max_map_count":
# sysctl vm.max_map_count
Se o valor for menor do que 262144, altere com o comando:
# sysctl -w vm.max_map_count=262144
Caso queira manter esta alteração após o reboot, insira a configuração no arquivo /etc/sysctl.conf.
Agora, subiremos um container baseado na imagem Docker baixada anteriormente:
# docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
A primeira execução do container é mais demorada devido à configuração inicial dos serviços. O shell no qual você executou o container ficará exibindo os logs do Elastic Stack. O container publicará no localhost às portas 5601/tcp para a interface web do Kibana, 9200/tcp para a interface JSON do Elasticsearch e 5044/tcp para o Logstash receber os logs do Filebeat.
Passos executados para instalação do Beat Filebeat. É importante instalar a versão do Filebeat idêntica à versão utilizada da imagem Docker do Elastic Stack, neste caso a 5.4.0.
Faça download do pacote:
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.4.0-x86_64.rpm
Instale o Filebeat:
# rpm -ivh filebeat-5.4.0-x86_64.rpm
Não inicie o serviço do Filebeat ainda, pois antes temos que configurar o Logstash e o Elasticsearch para receberem adequadamente os logs do Squid.
Configurando o Elastic Stack
Para configurar o Filebeat, edite o arquivo /etc/filebeat/filebeat.yml de forma que contenha este conteúdo.Com esta configuração, estamos dizendo ao Filebeat para que envie os logs do arquivo /var/log/squid/access.log, do tipo "squid", para o Logstash que está na porta 5044 do host elk. Como padrão do Filebeat, os índices criados no Elasticsearch terão o nome no formato "filebeat-%{+yyyy.MM.dd}" (por exemplo, "filebeat-2015.04.26").
Dois pontos de atenção antes de prosseguir:
Certificado → a imagem Docker utilizada já vem com um certificado pré-configurado para comunicação segura entre o Filebeat e Logstash. Crie o certificado no local configurado no arquivo /etc/filebeat/filebeat.yml, no caso /etc/pki/tls/certs/logstash-beats.crt.
Hostname → ao utilizar este certificado pré-configurado, sua distro deve resolver o nome "elk" para o IP do Logstash, no caso 127.0.0.1 (localhost). Para isso, no arquivo /etc/hosts, adicione ao fim linha que configura os nomes para o IP 127.0.0.1 o nome "elk". Esta linha na minha distro ficou assim:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 elk
Caso você queira gerar outro certificado e/ou alterar configurações de segurança, pode seguir as orientações na documentação da imagem Docker.
Agora, criaremos no Elasticsearch o modelo de índice "filebeat", disponibilizado com o Filebeat (/etc/filebeat/filebeat.template.json):
curl -XPUT 'http://elk:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json
Caso o modelo de índice tenha sido criado e enviado com sucesso ao Elasticsearch, você receberá o retorno:
{
"acknowledged" : true
}
Você recorda que o Elasticsearch é baseado em JSON e que o Kibana permite configurar e gerenciar o Elastic Stack? Então, vamos acessar a interface web do Kibana e conferir se o modelo de índice enviado está realmente lá.
Acesse via navegador o endereço http://localhost:5601, visualizando assim a interface web do Kibana que está sendo executado no container Docker. Conforme Figura 3, acesse o menu "Dev Tools", digite o comando "GET _template" na caixa à esquerda do console e clique no botão em forma de "play", conforme destacado na figura. Com isso, o Kibana apresentará na caixa à direita do console o retorno em formato JSON da configuração do modelo de índice.

Figura 3 - Consultando modelos de índice no Kibana
Para fazer isso, basta colar o conteúdo deste arquivo na caixa à esquerda do console do Kibana e clicar no botão em forma de "play" (Figura 4):

Figura 4 - Aplicando modelo de índice via Kibana
Também definimos a categoria (type) "squid" com os campos "squid.access.geoip.location" para receber dados do tipo "geo_point" e "squid.access.src_ip" e "squid.access.dst_ip" para receber dados do tipo IP. Os demais campos respeitarão a definição do modelo de índice padrão do Filebeat, ou seja, receberão dados do tipo "keyword".
Agora, para configurarmos o Logstash, você precisará acessar o shell do container Docker. Para isso, execute o comando:
# docker exec -it elk /bin/bash
Acesse o diretório de configuração do Logstash:
# cd /etc/logstash/conf.d
Crie neste diretório o arquivo de configuração "squid.conf", responsável por dizer ao Logstash como tratar os logs do Squid enviados pelo Filebeat. O conteúdo do arquivo deve ser este.
Entendendo o que esta configuração diz ao Logstash: criamos um filtro no qual, caso a mensagem recebida for do tipo "squid" (atributo "document_type" da configuração do Filebeat), utilizamos o plugin "grok" para estruturar o texto das linhas de log do Squid e depois utilizamos o plugin "geoip" para armazenar informações geográficas dos endereços IP acessados pelos clientes do Proxy Squid.
Destaque aqui para o plugin "grok", que é atualmente a melhor forma de o Logstash transformar dados desestruturados (texto) em algo estruturado e rastreável. Este plugin é perfeito para logs como Syslog, Apache, Nginx, MySQL e, em geral, qualquer formato de log geralmente escrito para humanos. Você basicamente utiliza expressões regulares para detectar os dados do texto e estruturá-los.
O Logstash possui cerca de 120 padrões prontos (patterns). Se você precisar de ajuda na construção dos seus próprios patterns, os sites grokdebug.herokuapp e grokconstructor.appspot serão bastante úteis.
Caso queira verificar os detalhes do "grok", veja a documentação oficial.
Para aplicar a nova configuração do Logstash, reinicie o serviço (ainda no shell do container):
# service logstash restart
Com a configuração ok, agora podemos iniciar o serviço do Filebeat:
# systemctl start filebeat.service
Não confunda os shells, pois o Filebeat está instalado no Fedora junto com o Squid, e não no container Docker.
Para que o Squid comece a gerar logs de acesso, você precisa navegar utilizando o proxy. Você pode alterar a configuração de proxy do Firefox (Figura 5) para navegar através do seu Squid:

Figura 5 - Configuração de proxy do navegador
No momento da criação do índice, você poderá visualizar no log que será exibido no shell do container (Figura 6):
Figura 6 - Índice criado pelo Elasticsearch