O Kernel Linux
O artigo refere-se à estrutura e funcionamento do Kernel Linux, com algumas sugestões de configurações.

Parte 4: Inicialização do Linux
Diferentemente de outros sistemas operacionais, no GNU/Linux, apenas parte dos drivers é carregada na memória durante a inicialização. A maioria pode ser carregada dinamicamente quando necessário.
Por este comportamento "modular" do sistema é que se costuma referir como "módulos de dispositivo", ao invés do termo "drivers", mais usual. Ou seja, esse é o suporte do carregamento dinâmico dos módulos.
O espaço será alocado e desalocado da memória de acordo com o uso. O Windows (Microsoft) carrega a maior parte dos drivers durante a inicialização e seu kernel híbrido mescla micronúcleo (microkernel), núcleo monolítico (kernel monolítico) e sei lá mais o quê.
Com os comandos modprobe, insmode, rmmode, etc, podemos carregar e descarregar os módulos no Linux. Seria o equivalente, grosso modo, a parar e iniciar processos no gerenciador de tarefas e/ou na janela Serviços (comando "services.msc") no Windows.
Quando compilamos um novo kernel com o comando make, os módulos são compilados junto (o comando make modules não é mais necessário), mas precisamos instalá-los (make modules_install) abaixo de "/lib/modules" e depois, instalamos todo o pacote compilado com make install abaixo de "/boot".
Em algumas distribuições, após a compilação, é aconselhável criar um initrd para o kernel, principalmente se tiver dois ou mais kernels ou dois ou mais sistemas instalados na máquina.
Fala-se "abaixo de /boot" em vez de "dentro de /boot", porque o sistema de arquivos tem um diretório principal que é o raiz "/" (root - não confunda com o superusuário), que fica no topo da estrutura e vai se dividindo em diretórios e arquivos, semelhante a uma árvore de cabeça para baixo, onde a raiz transforma-se em tronco e vai dividindo-se em galhos (diretórios) onde "nascem" as folhas (pastas e arquivos).
Um sistema de arquivos (ext3, ext4, ReiserFS, etc), difere do outro, basicamente, na forma como gerencia os diretórios, pastas e arquivos. Não esqueça que no GNU/Linux, tudo é tratado como arquivo, sendo que os diretórios, arquivos, dispositivos e etc, são diferenciados através das informações do cabeçalho.
Seguindo na mesma analogia da árvore, um sistema de arquivos seria uma laranjeira, outro seria uma pitangueira, um limoeiro, etc, onde você cuida da raiz, dos galhos e das folhas para colher os frutos da satisfação de ter um Linux bem configurado. Poético.
Para o kernel ter suporte a um determinado sistema de arquivos, ele precisa ser configurado e depois compilado com tal suporte. No Linux, você pode ter cada partição formatada num sistema de arquivos diferente, você pode até mesmo criar um diretório (ponto de montagem) e montá-lo num sistema de arquivos diferente, bastando o kernel ter suporte ao sistema desse arquivo.
Ex.:
# mount -t reiser4 /dev/sda1 /mnt/sda1
Uma versão de kernel não pode utilizar os módulos de outra versão, ou vice versa, portanto, devem existir em /lib/modules e /boot tantos diretórios de módulos, quantas forem as versões de kernel que forem compiladas.
Estes módulos fornecem suporte ao hardware e a todos os demais dispositivos (ex.: sistema de arquivos) que devem ser manipulados pelo sistema operacional, sendo construídos junto com o kernel.
Assim, por exemplo, caso existam as versões numéricas de kernel compiladas no seu sistema "2.6.34.14" e "3.8.3", existirão dois diretórios abaixo de /lib/modules:
# cd /lib/modules
O kernel do Linux incorporou algumas características de um kernel modular (microkernel), mas todo o kernel, incluindo os drivers de dispositivo e outros componentes, ainda formam um único bloco de código gigantesco, sendo que podem ser compilados separadamente na forma de módulos.
Estes módulos podem ser carregados e descarregados a qualquer tempo, como seria possível num kernel modular, porém, sem a perda de desempenho ou aumento da complexidade que existiria ao utilizar um kernel realmente modular (microkernel).
Isto significa que um módulo, apesar de não estar no mesmo código do kernel, é executado no espaço de memória do kernel. Sendo assim, apesar de modular, o kernel monolítico continua sendo único e centralizado.
A desvantagem é que os módulos compilados para uma determinada versão do kernel não podem ser usados em outras máquinas que utilizem versões diferentes. Mesmo drivers binários precisam ser primeiro transformados em módulos utilizando o código fonte, ou os headers (cabeçalhos) do kernel atual, para só depois poderem ser usados.
Analogamente falando, imaginem um planeta, e ao redor deste planeta estão orbitando seus satélites, luas, anéis e afins, atraídos pela gravidade do planeta. O kernel é o planeta; o espaço de memória do kernel é a gravidade; os satélites, luas, anéis e afins são os programas, módulos (drivers), aplicativos, etc; e o GNU/Linux é o sistema todo.
Veja bem, o Linux é, basicamente, um kernel ocupando seu próprio espaço na memória com suas bibliotecas, seus compiladores, suas ferramentas e seus utilitários.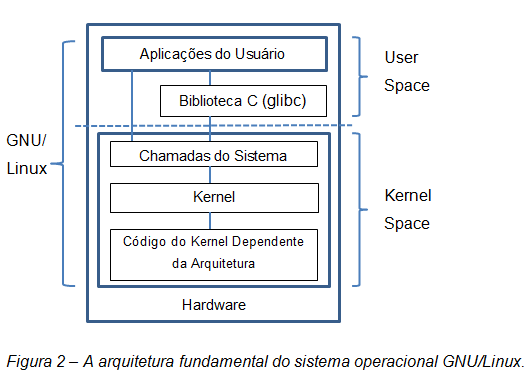 Fonte: http://www.ibm.com/developerworks/linux/library/l-linux-kernel/index.htm
Fonte: http://www.ibm.com/developerworks/linux/library/l-linux-kernel/index.htm
Dê uma boa olhada na figura acima e vamos analisá-la.
Na parte superior, temos o espaço do usuário (user space) ou do aplicativo. Este é o espaço no qual os aplicativos de usuário são executados. Abaixo do espaço do usuário, está o espaço do kernel (kernel space). Aqui, o Kernel Linux existe.
Adaptado de: Briga de Conceitos - Kernel x User «www.linuxsecurity.com.br
Adaptado de: Micro-Kernel ou Kernel Monolítico? « localdomain.wordpress.com
Linus Torvalds incluiu no Kernel Linux uma API estável para drivers no user space, desde a sua versão 2.6.23. Com esta API, em muitos casos, qualquer interessado pode manter a compatibilidade do pequeno trecho que roda no espaço do kernel, e o sistema pode manter-se em funcionamento e atualizado, independente de manutenção na parte que roda no espaço do usuário.
A proposta não foi de colocar código fechado dentro do kernel, mas sim de estabelecer uma API estável para que o kernel possa utilizar drivers fechados com mais facilidade. Nesta versão do kernel, o Xen também foi incluído na "árvore" principal.
Palavras do próprio Linus.
Apesar de que nenhum driver relevante usa essa API (drivers de vídeo, firewire, wireless, drivers de alta velocidade, etc), isso não deixa de ser uma ousadia, pois fez alguns pensarem que o Kernel Linux se tornara híbrido, o que não é verdade.
Adaptado de: Anatomia do Kernel Linux « www.ibm.com
Abaixo do kernel (veja figura 2), está o código dependente da arquitetura (Architecture-Dependent Kernel Code), que forma o que é mais comumente chamado de BSP (Board Support Package). Este código atua como o processador e como o código específico da plataforma para a arquitetura em questão.
No Linux, um processo é mais do que um programa em execução. Dois ou mais processos podem executar o mesmo programa e compartilhar diversos recursos. Outro nome para um processo é tarefa.
O kernel Linux, de um modo geral, refere-se aos processos como tarefas, porém, especificamente falando, um programa em execução no kernel space é uma tarefa e um programa em execução no user space é um processo.
Adaptado de: Espaço do enderaçamento do processo « www2.comp.ufscar.br
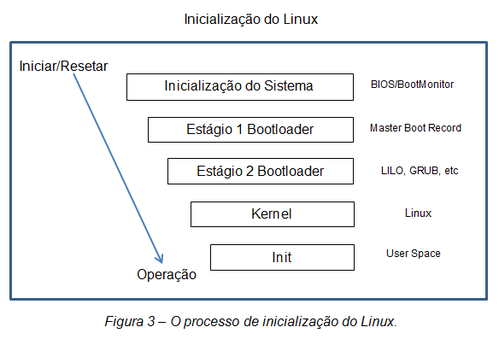 Fonte: Inside the Linux boot process « www.ibm.com
Fonte: Inside the Linux boot process « www.ibm.com
Quando um computador é ligado ou resetado, a CPU (entenda-se aqui, por CPU o conjunto placa-mãe + processador + memória RAM) é inicializada e o processador procura o Sistema Básico de Entrada e Saída (Basic Input/Output System), conhecido como BIOS, que é um programa, geralmente escrito em Assembly, que está armazenado na memória ROM (Read Only Memory) da placa-mãe.
O BIOS reconhece o setor de MBR (Master Boot Record - Registro Mestre de Inicialização), se houver um e não estiver corrompido, e carrega ele para a RAM e o executa.
O MBR - os primeiros 512 bytes do HD - carrega o gerenciador de boot (LILO, GRUB, etc) que, por sua vez, "chamará" o kernel que procurará o init (veja a figura 3). No Windows, o MBR carrega o arquivo Ntldr (pré-boot e boot) que por sua vez, "chama" o "boot.ini" dando início a toda a sequência de boot do Windows.
Quando o gerenciador de boot (GRUB, LILO, etc.) é executado na memória RAM, uma tela de splash é exibida e o sistema de arquivos temporários da raiz é carregado na memória RAM.
Quando as imagens são carregadas, o gerenciador de boot passa o controle para a imagem do kernel e ela é descompactada e inicializada. Nesta fase, o hardware do sistema é checado, os dispositivos são anexados, o dispositivo raiz é montado e os módulos necessários do kernel são carregados.
Quando o kernel conclui o carregamento dos módulos, ele inicia a primeira aplicação do User Space, o init, e a inicialização de alto nível do sistema é realizada. No Linux, a primeira aplicação iniciada comumente é a /sbin/init, conforme está configurada através do /etc/inittab.
O Initrd (Initial Ramdisk) - não confunda com o init - é carregado na memória RAM junto com o kernel e montado antes da partição raiz, como se fosse uma partição sem sistema de arquivos. O Initial Ramdisk tem a função de oferecer suporte ao sistema de arquivos da partição raiz e suporte à controladora de disco (SCSI, RAID, etc).
Repetindo: o Initrd é carregado junto com o kernel e depois vem o init que é, praticamente, o final da inicialização do Linux, ou seja, quando init "sobe", aparece a tela de login do sistema.
Aquele erro tipo "Kernel Panic: VFS: Unable to mount root fs", é provocado, em parte, pela falta do Initrd e acontece ANTES do init ser executado.
Por este comportamento "modular" do sistema é que se costuma referir como "módulos de dispositivo", ao invés do termo "drivers", mais usual. Ou seja, esse é o suporte do carregamento dinâmico dos módulos.
O espaço será alocado e desalocado da memória de acordo com o uso. O Windows (Microsoft) carrega a maior parte dos drivers durante a inicialização e seu kernel híbrido mescla micronúcleo (microkernel), núcleo monolítico (kernel monolítico) e sei lá mais o quê.
Com os comandos modprobe, insmode, rmmode, etc, podemos carregar e descarregar os módulos no Linux. Seria o equivalente, grosso modo, a parar e iniciar processos no gerenciador de tarefas e/ou na janela Serviços (comando "services.msc") no Windows.
Quando compilamos um novo kernel com o comando make, os módulos são compilados junto (o comando make modules não é mais necessário), mas precisamos instalá-los (make modules_install) abaixo de "/lib/modules" e depois, instalamos todo o pacote compilado com make install abaixo de "/boot".
Em algumas distribuições, após a compilação, é aconselhável criar um initrd para o kernel, principalmente se tiver dois ou mais kernels ou dois ou mais sistemas instalados na máquina.
Fala-se "abaixo de /boot" em vez de "dentro de /boot", porque o sistema de arquivos tem um diretório principal que é o raiz "/" (root - não confunda com o superusuário), que fica no topo da estrutura e vai se dividindo em diretórios e arquivos, semelhante a uma árvore de cabeça para baixo, onde a raiz transforma-se em tronco e vai dividindo-se em galhos (diretórios) onde "nascem" as folhas (pastas e arquivos).
Um sistema de arquivos (ext3, ext4, ReiserFS, etc), difere do outro, basicamente, na forma como gerencia os diretórios, pastas e arquivos. Não esqueça que no GNU/Linux, tudo é tratado como arquivo, sendo que os diretórios, arquivos, dispositivos e etc, são diferenciados através das informações do cabeçalho.
Seguindo na mesma analogia da árvore, um sistema de arquivos seria uma laranjeira, outro seria uma pitangueira, um limoeiro, etc, onde você cuida da raiz, dos galhos e das folhas para colher os frutos da satisfação de ter um Linux bem configurado. Poético.
Para o kernel ter suporte a um determinado sistema de arquivos, ele precisa ser configurado e depois compilado com tal suporte. No Linux, você pode ter cada partição formatada num sistema de arquivos diferente, você pode até mesmo criar um diretório (ponto de montagem) e montá-lo num sistema de arquivos diferente, bastando o kernel ter suporte ao sistema desse arquivo.
Ex.:
# mount -t reiser4 /dev/sda1 /mnt/sda1
Uma versão de kernel não pode utilizar os módulos de outra versão, ou vice versa, portanto, devem existir em /lib/modules e /boot tantos diretórios de módulos, quantas forem as versões de kernel que forem compiladas.
Estes módulos fornecem suporte ao hardware e a todos os demais dispositivos (ex.: sistema de arquivos) que devem ser manipulados pelo sistema operacional, sendo construídos junto com o kernel.
Assim, por exemplo, caso existam as versões numéricas de kernel compiladas no seu sistema "2.6.34.14" e "3.8.3", existirão dois diretórios abaixo de /lib/modules:
# cd /lib/modules
O kernel do Linux incorporou algumas características de um kernel modular (microkernel), mas todo o kernel, incluindo os drivers de dispositivo e outros componentes, ainda formam um único bloco de código gigantesco, sendo que podem ser compilados separadamente na forma de módulos.
Estes módulos podem ser carregados e descarregados a qualquer tempo, como seria possível num kernel modular, porém, sem a perda de desempenho ou aumento da complexidade que existiria ao utilizar um kernel realmente modular (microkernel).
Isto significa que um módulo, apesar de não estar no mesmo código do kernel, é executado no espaço de memória do kernel. Sendo assim, apesar de modular, o kernel monolítico continua sendo único e centralizado.
A desvantagem é que os módulos compilados para uma determinada versão do kernel não podem ser usados em outras máquinas que utilizem versões diferentes. Mesmo drivers binários precisam ser primeiro transformados em módulos utilizando o código fonte, ou os headers (cabeçalhos) do kernel atual, para só depois poderem ser usados.
Analogamente falando, imaginem um planeta, e ao redor deste planeta estão orbitando seus satélites, luas, anéis e afins, atraídos pela gravidade do planeta. O kernel é o planeta; o espaço de memória do kernel é a gravidade; os satélites, luas, anéis e afins são os programas, módulos (drivers), aplicativos, etc; e o GNU/Linux é o sistema todo.
Veja bem, o Linux é, basicamente, um kernel ocupando seu próprio espaço na memória com suas bibliotecas, seus compiladores, suas ferramentas e seus utilitários.

Dê uma boa olhada na figura acima e vamos analisá-la.
Na parte superior, temos o espaço do usuário (user space) ou do aplicativo. Este é o espaço no qual os aplicativos de usuário são executados. Abaixo do espaço do usuário, está o espaço do kernel (kernel space). Aqui, o Kernel Linux existe.
"Kernel Space é o nome dado ao espaço de programação e execução do lado kernel. O kernel envia respostas às solicitações dos programas, programas estes que são executados no user space.
O user space é o nome dado para a programação e execução de instruções no ambiente que conhecemos e usamos (shell). Em ambiente Linux, para que o user space possa interagir com o kernel space, é usado um recurso conhecido como System Calls.
As System Calls (chamadas do sistema) são responsáveis por passar informações como funções e parâmetros de funções a uma linguagem de mais baixo nível, entendível pelo kernel.
O user space é, em sua totalidade, dependente do kernel space, pois manipula informações recebidas pelo kernel. Um erro que ocorra no kernel space, refletirá no user space, caso alguém ataque o kernel space falsificando informações, o user space será afetado."
Adaptado de: Briga de Conceitos - Kernel x User «www.linuxsecurity.com.br
"O Linux é um kernel monolítico, mas que pode possuir módulos. Porém, possuir módulos não o torna necessariamente um microkernel, pois o módulos são executados no kernel space, ao contrário do que ocorre com os microkernels, onde os recursos externos são executados no user space."
Adaptado de: Micro-Kernel ou Kernel Monolítico? « localdomain.wordpress.com
Linus Torvalds incluiu no Kernel Linux uma API estável para drivers no user space, desde a sua versão 2.6.23. Com esta API, em muitos casos, qualquer interessado pode manter a compatibilidade do pequeno trecho que roda no espaço do kernel, e o sistema pode manter-se em funcionamento e atualizado, independente de manutenção na parte que roda no espaço do usuário.
A proposta não foi de colocar código fechado dentro do kernel, mas sim de estabelecer uma API estável para que o kernel possa utilizar drivers fechados com mais facilidade. Nesta versão do kernel, o Xen também foi incluído na "árvore" principal.
"Esta interface permite escrever a maioria do driver em espaço de usuário, com um pedaço muito pequeno de fato no kernel. Utiliza um dispositivo "char" e "sysfs" para interagir com o processo em espaço de usuário para processar interrupções e controlar acessos à memória".
Palavras do próprio Linus.
Apesar de que nenhum driver relevante usa essa API (drivers de vídeo, firewire, wireless, drivers de alta velocidade, etc), isso não deixa de ser uma ousadia, pois fez alguns pensarem que o Kernel Linux se tornara híbrido, o que não é verdade.
"Há também a GNU C Library (glibc). Ela fornece a interface de chamada do sistema que se conecta ao kernel e fornece o mecanismo para transição entre o aplicativo de espaço de usuário e o kernel. Isso é importante, pois o kernel e o aplicativo do usuário ocupam espaços de endereços de memória diferentes e protegidos. E embora cada processo de espaço de usuário ocupe seu próprio espaço de endereço virtual, o kernel ocupa um único espaço de endereço.
O Kernel Linux pode ainda ser dividido em três níveis completos. Na parte superior, temos a interface de chamada do sistema (System Call Interface) que implementa as funções básicas, como read (leitura) e write (escrita).
Abaixo da interface de chamada do sistema está o código do kernel (Kernel), que pode ser mais precisamente definido como o código do kernel independente da arquitetura. Esse código é comum a todas as arquiteturas do processador às quais o Linux oferece suporte."
Adaptado de: Anatomia do Kernel Linux « www.ibm.com
Abaixo do kernel (veja figura 2), está o código dependente da arquitetura (Architecture-Dependent Kernel Code), que forma o que é mais comumente chamado de BSP (Board Support Package). Este código atua como o processador e como o código específico da plataforma para a arquitetura em questão.
No Linux, um processo é mais do que um programa em execução. Dois ou mais processos podem executar o mesmo programa e compartilhar diversos recursos. Outro nome para um processo é tarefa.
O kernel Linux, de um modo geral, refere-se aos processos como tarefas, porém, especificamente falando, um programa em execução no kernel space é uma tarefa e um programa em execução no user space é um processo.
"No espaço do usuário, os processos são representados por identificadores de processo (PIDs). Na perspectiva do usuário, um PID é um valor numérico que identifica exclusivamente o processo. Um PID não é alterado durante o ciclo de vida de um processo, mas pode ser reutilizado depois que o processo termina, portanto, nem sempre é ideal armazená-lo em cache."
Adaptado de: Espaço do enderaçamento do processo « www2.comp.ufscar.br

Quando um computador é ligado ou resetado, a CPU (entenda-se aqui, por CPU o conjunto placa-mãe + processador + memória RAM) é inicializada e o processador procura o Sistema Básico de Entrada e Saída (Basic Input/Output System), conhecido como BIOS, que é um programa, geralmente escrito em Assembly, que está armazenado na memória ROM (Read Only Memory) da placa-mãe.
O BIOS reconhece o setor de MBR (Master Boot Record - Registro Mestre de Inicialização), se houver um e não estiver corrompido, e carrega ele para a RAM e o executa.
O MBR - os primeiros 512 bytes do HD - carrega o gerenciador de boot (LILO, GRUB, etc) que, por sua vez, "chamará" o kernel que procurará o init (veja a figura 3). No Windows, o MBR carrega o arquivo Ntldr (pré-boot e boot) que por sua vez, "chama" o "boot.ini" dando início a toda a sequência de boot do Windows.
Quando o gerenciador de boot (GRUB, LILO, etc.) é executado na memória RAM, uma tela de splash é exibida e o sistema de arquivos temporários da raiz é carregado na memória RAM.
Quando as imagens são carregadas, o gerenciador de boot passa o controle para a imagem do kernel e ela é descompactada e inicializada. Nesta fase, o hardware do sistema é checado, os dispositivos são anexados, o dispositivo raiz é montado e os módulos necessários do kernel são carregados.
Quando o kernel conclui o carregamento dos módulos, ele inicia a primeira aplicação do User Space, o init, e a inicialização de alto nível do sistema é realizada. No Linux, a primeira aplicação iniciada comumente é a /sbin/init, conforme está configurada através do /etc/inittab.
O Initrd (Initial Ramdisk) - não confunda com o init - é carregado na memória RAM junto com o kernel e montado antes da partição raiz, como se fosse uma partição sem sistema de arquivos. O Initial Ramdisk tem a função de oferecer suporte ao sistema de arquivos da partição raiz e suporte à controladora de disco (SCSI, RAID, etc).
Repetindo: o Initrd é carregado junto com o kernel e depois vem o init que é, praticamente, o final da inicialização do Linux, ou seja, quando init "sobe", aparece a tela de login do sistema.
Aquele erro tipo "Kernel Panic: VFS: Unable to mount root fs", é provocado, em parte, pela falta do Initrd e acontece ANTES do init ser executado.