OCR - converter imagens em texto

Publicado por Xerxes em 22/09/2022
[ Hits: 6.225 ]

OCR - converter imagens em texto
O que é OCR? Optical Character Recognition, em português, Reconhecimento Óptico de Caracteres.
Para converter o texto a partir de uma imagem em texto puro, faça o seguinte.
Instale o tesseract:
sudo apt install tesseract-ocr
E um idioma:
sudo apt-get install tesseract-ocr-[IDIOMA]
Exemplo para português:
sudo apt-get install tesseract-ocr-por
Ou pode instalar todos os idiomas:
sudo apt-get install tesseract-ocr-all
Os idiomas são: afr, amh, ara, asm, aze, aze-cyrl, bel, ben, bod, bos, bul, cat, ceb, ces, chi-sim, chi-tra, chr, cym, dan, dan-frak, deu, deu-frak, dev, dzo, ell, eng, enm, epo, est, eus, fas, fin, fra, frk, frm, gle, gle-uncial, glg, grc, guj, hat, heb, hin, hrv, hun, iku, ind, isl, ita, ita-old, jav, jpn, kan, kat, kat-old, kaz, khm, kir, kor, kur, lao, lat, lav, lit, mal, mar, mkd, mlt, msa, mya, nep, nld, nor, ori, pan, pol, por, pus, ron, rus, san, sin, slk, slk-frak, slv, spa, spa-old, sqi, srp, srp-latn, swa, swe, syr, tam, tel, tgk, tgl, tha, tir, tur, uig, ukr, urd, uzb, uzb-cyrl, vie, yid, yor
Para realizar a conversão com idioma português, veja um exemplo:
tesseract -l por imagem_entrada.png arquivo_saida
O comando tesseract reconhece texto em uma imagem fornecida e o armazena em um arquivo de saída especificado. O parâmetro -l (de "language") especifica o idioma do texto na imagem fornecida. Isso vai gerar o "arquivo_saida.txt".
Basta ver o resultado com:
cat arquivo_saida.txt
Veja uma imagem com exemplo:
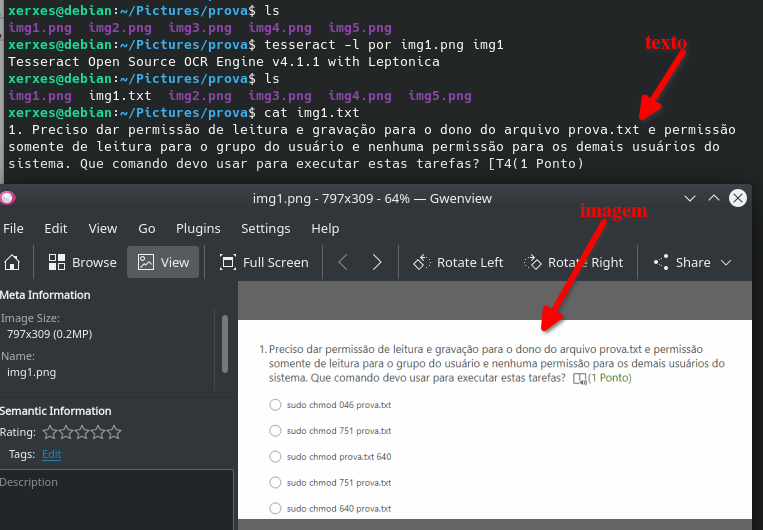
- ocr - How do I install a new language pack for Tesseract on 16.04 - Ask Ubuntu
- How To Convert Images To Text On The Linux Command Line With OCR
Google Chrome para Linux aqui!
Cube 2: Collect Edition (jogo FPS)
Estilizando o i3lock no seu ambiente i3
Função Snap no LXDE pela gambiarra do Xfwm4 (Debian)
Pós-instalação do Fedora 22 ou superior
Removendo a mensagem de erro vboxclient na inicialização LinuxMint-17x e LMDE-2
Recuperando inicialização do Slackware após atualização do kernel via slackpkg
Desligar e Reiniciar o Linux pelo Terminal - Todas as Formas Possíveis
Legal!!!!
#-------------------------------------------------------------------------------------#
"Falar é fácil, me mostre o código." - Linus Torvalds
#-------------------------------------------------------------------------------------#
Bem legal. Já anotado.
___________________________________________________________
Conhecimento não se Leva para o Túmulo.
https://github.com/mxnt10
Patrocínio

Destaques
Artigos
Boas Práticas e Padrões Idiomáticos em Go e C
Vale a pena ter mais de uma interface grafica no seu Linux?
Estrutura e Funcionamento de um Ebuild no Gentoo Linux
Dicas
Copiar Para e Mover Para no menu de contexto do Nautilus e Dolphin
Dotando o Thunar das opcoes Copiar para e Mover para no menu de contexto
Usando o ble.sh (Bash Line Editor) no lugar do bash completion
Montagem pré automática de HD externo usb em NTFS não funciona no Debian Trixie - Solução
Tópicos
Instalação Dual Boot Linux+Windows 11 (4)
No Ubuntu 26.04, sudo passou a mostrar os asteriscos ao digitar por pa... (5)
Como instalar Warsaw no Gentoo? (0)
Como insiro e excluo um elemento XML e JSON ao código Javascript (1)
Top 10 do mês
-

Xerxes
1° lugar - 126.997 pts -

Fábio Berbert de Paula
2° lugar - 65.243 pts -

Buckminster
3° lugar - 39.443 pts -

Alberto Federman Neto.
4° lugar - 33.925 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 23.034 pts -

edps
6° lugar - 21.875 pts -

Daniel Lara Souza
7° lugar - 20.799 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 19.749 pts -

Sidnei Serra
9° lugar - 19.573 pts -

Andre (pinduvoz)
10° lugar - 16.012 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: