Container Elastic Stack para visualização de logs do Proxy Squid
Compartilho neste artigo a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.

Introdução
Muitas vezes um profissional de TI precisa monitorar, analisar e/ou apresentar dados gerados por uma determinada fonte, como os logs de um serviço ou aplicação. Devem existir excelentes ferramentas, open source ou proprietárias, para auxiliar nesta tarefa, mas que podem ser pouco flexíveis e/ou não atender totalmente à necessidade.
Compartilho neste artigo, a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.
Breve descrição retirada do site da Elastic:
Beats → são agentes que você instala em seus servidores para enviar diferentes tipos de dados ao Elasticsearch. Os Beats podem enviar dados diretamente ao Elasticsearch ou enviá-los ao Elasticsearch via Logstash, o qual pode ser utilizado para analisar e transformar os dados.
Dentre os Beats disponívels, utilizaremos o Filebeat, que é um coletor de dados de log para arquivos locais. Instalado como um agente nos servidores, o Filebeat monitora os diretórios de log ou arquivos de log específicos e encaminha o conteúdo ao Elasticsearch (diretamente ou via Logstash) para indexação, atuando como um centralizador de logs. Neste artigo, o Filebeat será responsável por monitorar e encaminhar ao Logstash o conteúdo do arquivo de log de acesso do Squid.
Logstash → é um mecanismo de coleta de dados com capacidades de pipeline de tempo real. O Logstash pode unir dinamicamente dados de fontes diferentes e normalizar os dados em destinos de sua escolha. Neste artigo, o Logstash receberá e normalizará os logs do Squid, os enviando posteriormente ao Elasticsearch.
Elasticsearch → é um mecanismo de pesquisa e análise distribuído baseado em JSON, projetado para escalabilidade horizontal, máxima confiabilidade e gerenciamento fácil. Permite armazenar, pesquisar e analisar rapidamente grandes volumes de dados. Ele será o responsável por armazenar e indexar os dados enviados pelos Logstash, permitindo buscar estes dados praticamente em tempo real.
Seguem alguns conceitos importantes referente ao Elasticsearch:
Kibana → é uma plataforma de análise e visualização projetada para trabalhar com o Elasticsearch, além de permitir configurar e gerenciar todos os aspectos do Elastic Stack. Você usa o Kibana para pesquisar, visualizar e interagir com dados armazenados em índices Elasticsearch. Você pode facilmente realizar análises avançadas de dados e visualizá-las em uma variedade de gráficos, tabelas e mapas.
Utilizaremos o Kibana para visualizar as informações armazenadas e indexadas no Elasticsearch.
Pode-se observar na Figura 1 o fluxo da comunicação entre os mecanismos do Elastic Stack com os logs de acesso do Squid.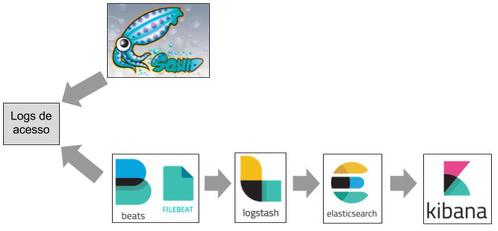
Figura 1
Compartilho neste artigo, a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.
Breve descrição retirada do site da Elastic:
Open Source Elastic Stack: Obtenha dados confiáveis e seguros de qualquer fonte, em qualquer formato e procure, analise e visualize em tempo real.
Ferramentas
O Elastic Stack é formado pelas seguintes ferramentas:Beats → são agentes que você instala em seus servidores para enviar diferentes tipos de dados ao Elasticsearch. Os Beats podem enviar dados diretamente ao Elasticsearch ou enviá-los ao Elasticsearch via Logstash, o qual pode ser utilizado para analisar e transformar os dados.
Dentre os Beats disponívels, utilizaremos o Filebeat, que é um coletor de dados de log para arquivos locais. Instalado como um agente nos servidores, o Filebeat monitora os diretórios de log ou arquivos de log específicos e encaminha o conteúdo ao Elasticsearch (diretamente ou via Logstash) para indexação, atuando como um centralizador de logs. Neste artigo, o Filebeat será responsável por monitorar e encaminhar ao Logstash o conteúdo do arquivo de log de acesso do Squid.
Logstash → é um mecanismo de coleta de dados com capacidades de pipeline de tempo real. O Logstash pode unir dinamicamente dados de fontes diferentes e normalizar os dados em destinos de sua escolha. Neste artigo, o Logstash receberá e normalizará os logs do Squid, os enviando posteriormente ao Elasticsearch.
Elasticsearch → é um mecanismo de pesquisa e análise distribuído baseado em JSON, projetado para escalabilidade horizontal, máxima confiabilidade e gerenciamento fácil. Permite armazenar, pesquisar e analisar rapidamente grandes volumes de dados. Ele será o responsável por armazenar e indexar os dados enviados pelos Logstash, permitindo buscar estes dados praticamente em tempo real.
Seguem alguns conceitos importantes referente ao Elasticsearch:
- Index (índice): é como uma tabela de um banco de dados relacional. É uma coleção de documentos com características semelhantes. Por exemplo, podemos ter um índice para dados de clientes, outro para catálogo de produtos e outro para dados de pedidos. Um índice é identificado por um nome (com letras minúsculas) que é usado para se referir ao índice ao executar operações de indexação, pesquisa, atualização e exclusão de documentos.
- Type (tipo): Dentro de um índice você pode definir um ou mais tipos de documentos. Um tipo é uma categoria/partição lógica do seu índice. Em geral, um tipo é definido para documentos que possuem um conjunto de campos comuns. Por exemplo, vamos assumir que você possua uma plataforma de blogs e armazena todos os seus dados em um único índice. Neste índice você pode definir um tipo de dados de usuário, outro de postagens e outro de comentários, cada tipo com seus campos (fields) específicos.
- Document (documento): é uma unidade básica de informação que pode ser indexada. É como uma linha em uma tabela de um banco de dados relacional. Por exemplo, você pode ter um documento para um único cliente e outro para um único produto. Este documento é expresso em JSON. Dentro de um índice/tipo você pode armazenar quantos documentos desejar. Observe que, embora um documento resida fisicamente em um índice, ele é indexado/atribuído a um tipo dentro de um índice. Por exemplo, armazenei um novo "documento" no "tipo comentário" do "índice blog".
- Fields and Datatypes (campos e tipos de dados): um documento possui uma lista de campos. Um campo é como uma coluna em uma tabela de um banco de dados relacional. Cada campo pode armazenar um determinado tipo de dado que pode ser mapeado dinamicamente ou explicitamente.
- Index Templates (modelos de índice): permitem que você defina modelos de configuração e mapeamento que serão automaticamente aplicados quando novos índices forem criados.
Kibana → é uma plataforma de análise e visualização projetada para trabalhar com o Elasticsearch, além de permitir configurar e gerenciar todos os aspectos do Elastic Stack. Você usa o Kibana para pesquisar, visualizar e interagir com dados armazenados em índices Elasticsearch. Você pode facilmente realizar análises avançadas de dados e visualizá-las em uma variedade de gráficos, tabelas e mapas.
Utilizaremos o Kibana para visualizar as informações armazenadas e indexadas no Elasticsearch.
Pode-se observar na Figura 1 o fluxo da comunicação entre os mecanismos do Elastic Stack com os logs de acesso do Squid.
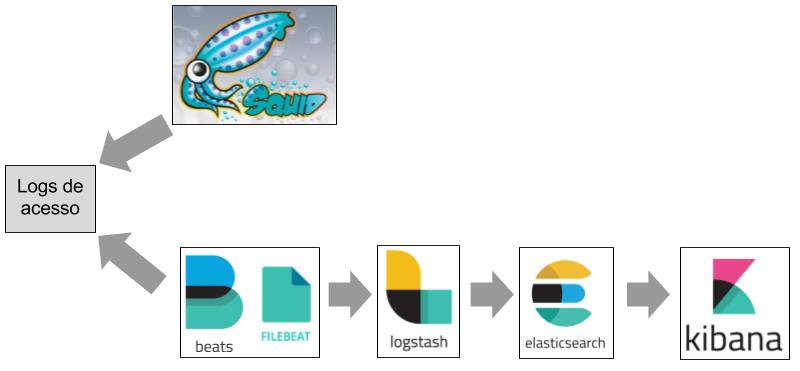
Figura 1