Liberando Memória ajustando o Tamanho das Strings em C
Recentemente apresentei o mesmo método em uma dica aqui mesmo no Viva o Linux. Criei esse artigo mais para os iniciantes para explicar em detalhes o funcionamento do código para liberar posições alocadas para a memória.
[ Hits: 3.935 ]
Por: Mauricio Ferrari em 24/05/2020 | Blog: https://www.youtube.com/@LinuxDicasPro

Introdução
Lá, eu fui direto e apresentei apenas as instruções. A dica que eu apresentei, só consegui encontrar em um curso que eu fiz na Udemy: Curso Completo de Linguagem C e C++ - Iniciante Ao Avançado | Udemy
Aqui, vou tentar detalhar ao máximo o método que eu apresentei. Esse método de liberar memória para o Computador pode fazer diferença no futuro de um programador, no caso de uma criação de um grande projeto no qual exige um grande consumo de memória.
ANALISANDO O CÓDIGO
Vamos analisar o código postado no Viva o Linux sem a string: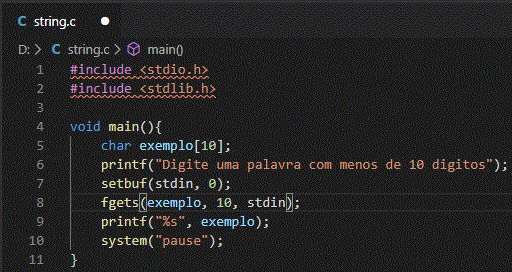
[ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ] [ 9 ]
A linha 8, o comando fgets espera a tecla enter ser pressionada para gravar a palavra digitada no buffer para a string exemplo. Vamos considerar que a palavra "ideia" foi digitada:
[ i ] [ d ] [ e ] [ i ] [ a ] [ ] [ ] [ ] [ ] [ \0 ]
A string foi gravada e como de costume o caractere nulo "\0" usado para finalizar a string para que o printf não imprima caracteres doidos, pois como se sabe, ele irá percorrer a memória até encontrá-lo.
Conforme o exemplo anterior, é notável quatro espaços de memória sem utilidade nenhuma para a string. Esses poderiam ser liberados para uso em outros processos na memória.
APLICANDO O MÉTODO AO CÓDIGO
Vamos analisar o código postado no Viva o Linux com a string: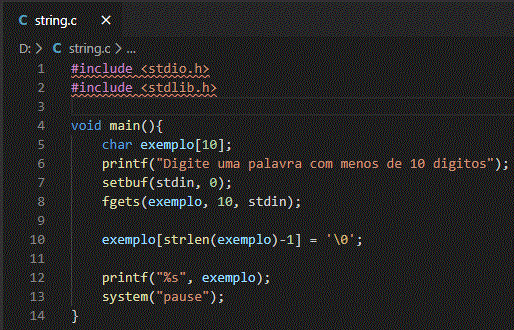
Vamos entender a situação, não sabemos o tamanho da string e ser digitada. Só é possível saber com o uso do strlen, que conta os caracteres de uma string. São 5 caracteres mais o caractere nulo, portanto 6. Vamos usar isso para inserir um caractere nulo no local apropriado, reduzindo o tamanho da string.
[ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ] [ 9 ]
[ i ] [ d ] [ e ] [ i ] [ a ] [ ] [ \0 ] [ ] [ ] [ ]
Vamos agora entender o que aconteceu, a aplicação do strlen conta 6 caracteres em exemplo e esse foi o valor passado para a string exemplo. É como se tivesse feito isso:
Ele gravou a string na posição 6 na memória e não na sexta posição da memória que é a posição 5. Por isso foi necessário corrigir esse problema reduzindo em um a posição na memória:
[ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ] [ 9 ]
[ i ] [ d ] [ e ] [ i ] [ a ] [ \0 ] [ ] [ ] [ ] [ ]
CONCLUSÃO
Assim, a string é devidamente reduzida liberando assim, todo o espaço restante para a memória. Parece pouco mas, pense em uma string com 250 posições da memória alocada, aí sim o método é de grande utilidade. Isso proporcionaria uma grande economia no uso da memória em programas muito grandes.Publicação original em meu site: Liberando Memória ajustando o Tamanho das Strings em C - Conteúdos - Linguagem C Fácil
Podem comentar lá também, ficarei feliz.
Aplicativos do Windows que já tiveram suporte no Linux
Como Funcionam as Cores em Hexadecimal
Abrindo aplicações Java de uma vez por todas
Compilando o QMPlay2 20.07.04 no Linux Mint 20 e Gerando o Pacote para Instalar
Introdução à linguagem C - Parte III
Criando uma calculadora com o KDevelop
Introdução as Bibliotecas do C/C++
[1] Comentário enviado por danniel-lara em 24/05/2020 - 14:46h
Muito bom , parabéns
Obrigado!
Você como programador C, o que me diz da linguagem Vala?
[3] Comentário enviado por Cizordj em 26/05/2020 - 09:27h
Você como programador C, o que me diz da linguagem Vala?
Não conhecia essa linguagem. Andei dando uma pesquisada e parece boa. Tem sintaxes bem parecida com C# inclusive. O que eu li de bom sobre ele é que ele possui uma vantagem em relação ao consumo de memória ram o que é muito bom. Porém, é mais destinado para o desenvolvimento de aplicações para o gnome. Não é de todo ruim, já que é possível instalar aplicações do gnome em outros ambientes gráficos.
Mas sem testar, não dá para dar uma nota. Olhando as documentações todas as linguagens parece ser boa. Por isso, só testando pra saber.
[4] Comentário enviado por mauricio123 em 26/05/2020 - 22:29h
[3] Comentário enviado por Cizordj em 26/05/2020 - 09:27h
Você como programador C, o que me diz da linguagem Vala?
Não conhecia essa linguagem. Andei dando uma pesquisada e parece boa. Tem sintaxes bem parecida com C# inclusive. O que eu li de bom sobre ele é que ele possui uma vantagem em relação ao consumo de memória ram o que é muito bom. Porém, é mais destinado para o desenvolvimento de aplicações para o gnome. Não é de todo ruim, já que é possível instalar aplicações do gnome em outros ambientes gráficos.
Mas sem testar, não dá para dar uma nota. Olhando as documentações todas as linguagens parece ser boa. Por isso, só testando pra saber.
Obrigado, é que eu tô tentando aprender alguma linguagem compilada orientada a objetos. Pelo visto o Vala vai ser interessante pra fazer o backend de algumas aplicações
Prezado mauricio123,
Acho importante observar que o título do artigo pode ser um pouco confundente, pois gravar um byte nulo ao final do texto da string não libera a memória para ela alocada, mas tão somente indica onde o texto que a compõe termina, só que esse terminar na verdade significa algo na linha de que, a partir daquele ponto, as funções do programa devem considerar não há mais caracteres relevantes. Pôr o byte nulo em qualquer posição de um [i]array[/i] de caracteres não muda em nada a quantidade de memória associada ao array.
(Você até pode se valer de que o texto contido no array termina antes do tamanho total para usar o espaço após o byte nulo com o propósito de guardar outras coisas, mas geralmente você vai ter trabalho adicional para ficar controlando onde residem os pedaços ocupados e os pedaços livres do array. Na prática isso seria uma reimplementação das funções de alocação e liberação de memória, e não é muito prático reinventar a roda se isso não for estritamente necessário.)
Juro que minha intenção é informar, e não desmerecer nada nem ninguém. Por isso mesmo acho importante apontar alguns pontos duvidosos no programa e nas informações que você postou, junto, quando cabível, com as respectivas correções.
A declaração de main como void main() tem dois erros em C (em C++, seria apenas um erro).
O tipo de retorno da função main tem de ser int. O uso de void é inadequado, pois o padrão de 2011 do C diz na §5.1.2.2.1 quais as duas possíveis declarações de main, e ambas empregam int como tipo de retorno (mas já era assim desde o padrão de 1989). Além disso, em C, a declaração de uma função com uma lista de parâmetros vazia (i.e. nada entre os parênteses que seguem o nome da função) significa que a função pode receber uma quantidade qualquer de argumentos de quaisquer tipos, sem que o compilador reclame (em C++, o sentido é diferente: uma lista vazia significa que a função não admite nenhum argumento). Isso também viola a §5.1.2.2.1, que diz que a função tem de ser declarada sem qualquer parâmetro, que corresponde a colocar a palavra-chave void dentro dos parênteses da declaração (i.e. int main(void)), ou que ela recebe um vetor de strings, representado através de dois parâmetros, sendo o primeiro um valor inteiro que indica a quantidade de elementos e o segundo, um array de ponteiros para caracteres (i.e. int main(int argc, char *argv[]), que é sinônimo de int main(int argc, char **argv), sendo argc uma abreviação de argument counter e argv abreviação de argument vector, mas esses nomes convencionais podem ser trocados por outros, se você preferir).
Alguma razão para usar setbuf(stdin, 0); no seu programa?
Pergunto porque há muita gente na Internet que recomenda usar setbuf/setvbuf para, supostamente, limpar o buffer do teclado. No entanto, tal recomendação, embora relativamente popular, é incorreta, pois o padrão do C não especifica que a função tenha esse comportamento, e mesmo que tal comportamento exista numa implementação em particular, nada garante que existirá em outras. O padrão especifica, isso sim, restrições sobre quando setbuf pode ser usada (§7.21.5.5 e §7.21.5.6).
Se de fato sua intenção era garanir um buffer de entrada sem caracteres indesejados, considere que, como seu programa mal começou a executar quando você faz a chamada, é certo que o buffer estará vazio, de modo que, na melhor das hipóteses, a operação seria inócua.
A explicação sobre a disposição dos caracteres na memória após a leitura com fgets está incorreta.
A chamada fgets(exemplo, 10, stdin), que foi o exemplo que você usou, tenta ler a partir de stdin uma quantidade máxima de 9 caracteres, encerrando a leitura se encontrar um caráter de fim de linha ou após ler o 9º caráter (o que acontecer primeiro; para também em caso de erro de leitura ou se o final dos dados de entrada for atingido). Assim que a leitura acaba, a função já armazena um byte nulo na posição imediatamente seguinte à do último caráter lido, que pode ser na 10ª posição mas também pode ser antes, caso uma das condições de interrupção da leitura seja encontrada antes da leitura do 9º caráter. Se a leitura parar porque encontrou o caráter de fim de linha, esse caráter é copiado para o destino da leitura (que, no seu caso, é o array exemplo). Assim sendo, se o usuário digitar a palavra ideia e apertar a tecla <Enter> imediatamente em seguida, o conteúdo do array exemplo será o seguinte:
{'i', 'd', 'e', 'i', 'a', '\n', '\0', byte_desconhecido, byte_desconhecido, byte_desconhecido} // Continua com dez elementos, embora os valores dos três últimos elementos não sejam manipulados pelo programa.
strlen(exemplo), nesse caso, retorna o valor 6 não porque são cinco caracteres lido mais o byte nulo, mas porque há, de fato, seis caracteres não-nulos antes do byte nulo, porque a quebra de linha faz parte dos dados lidos, e é armazenada na sexta posição do array, com o byte nulo na sétima posição, de maneira absolutamente coerente com o funcionamento que o padrão descreve para fgets (§7.21.7.2).
O comportamento de fgets de incluir o caráter de fim de linha no destino da leitura é importante para saber se a função parou porque encontrou realmente o final da linha ou se por falta de espaço para continuar lendo novos caracteres ou, ainda, se porque acabaram-se os dados para leitura ou ocorreu algum erro. Assim sendo, o correto seria você testar se realmente existe uma marca de fim de linha em exemplo[strlen(exemplo)-1] antes de substuí-la por um byte nulo. Por exemplo, se, em vez de ideia seguido de <Enter> você tivesse digitado paulo1205 seguido de <Enter> a leitura iria parar depois de ler o caráter '5' para a nona posição do array, e não consumiria o <Enter>, que ficaria no buffer de entrada até uma eventual operação de leitura posterior (que, não existe no seu programa, mas a função fgets não tem tal conhecimento). Na décima posição do array, entraria um byte nulo, marcando o fim da string. Nesse caso, strlen(exemplo) retornaria o valor 9, e a operação exemplo[strlen(exemplo)-1]='\0' faria com que o conteúdo da nona posição fosse sobrescrito. O resultado na memória seria o seguinte.
{'p', 'a', 'u', 'l', 'o', '1', '2', '0', '\0', '\0'} // Continua com dez elementos, e dois bytes nulos ao final (o último como parte do funcionamento normal de fgets, e o penúltimo pela sobrescrita forçada do 9º elemento, onde antes havia um '5').
A forma mais geral de usar fgets seria a seguinte:
if(fgets(array, tamanho_array, arq_origem)){
// Leu com sucesso pelo menos um caráter.
size_t indice_ultimo=strlen(array)-1;
if(array[indice_ultimo]=='\n'){
// Leu uma linha completa. Se você quiser, pode sobrescrever a quebra de linha com um byte nulo,
// encurtando o tamanho lógico da string (mas não o tamanho físico do array que a contém!).
array[indice_ultimo]='\0';
}
else{
// Faltou a marca de fim de linha. Para algumas aplicações, isso pode ser um problema sério.
if(indice_ultimo==tamanho_array-1){
// Faltou espaço no array.
/* Trata situação de falta de espaço. */
}
else{
// Não foi falta de espaço, mas sim uma interrupção prematura da leitura.
/* Trata situação de fim de dados prematuro, possivelmente usando funções como feof() e ferror() */
}
}
}
else{
// Não conseguiu ler nenhum caráter, e fgets() retornou erro.
/* Trata o erro de leitura, possivelmente usando ferror() e feof(). */
}
Uma dica quanto a printf("%s", exemplo) é que você sempre imprima uma quebra de linha após imprimir os dados, a não ser que tenha um bom motivo para não o fazer (por exemplo, se estiver imprimindo uma mensagem de prompt para uma operação de leitura, ou se a próxima coisa que você imprimir tiver de ficar na mesma linha). Em outras palavras, normalmente você usaria printf("%s\n", exemplo) ou, neste caso específico, em que você imprime só o conteúdo de exemplo puts(exemplo) (puts sempre imprime uma quebra de linha após a string).
system("pause") é uma instrução problemática, pois invocar comandos externos costuma ser muito ineficiente (sob o aspecto de desempenho), dependente das características de cada ambiente (analisando do ponto de vista de portabilidade) e potencialmente inseguro (sob o aspecto de segurança). No Linux, por exemplo, essa instrução não faz sentido, pois não existe o comando pause.
A conclusão do artigo dá o tom final da informação sobre economia de memória, mas infelizmente essa conclusão é falsa.
Você mencionou o curso da Udemy. Segui o link e examinei o conteúdo de um trecho de uma das aulas de C, que estava com acesso público, como um tipo de degustação. Fiquei um tanto assustado com a quantidade de bobagens ditas no vídeo e escritas como código em C por parte do instrutor. Pelo tanto de propaganda da Udemy que já recebi, sinceramente esperava algo menos amador.
... Então Jesus afirmou de novo: (...) eu vim para que tenham vida, e a tenham plenamente. (João 10:7-10)
[6] Comentário enviado por paulo1205 em 29/08/2021 - 06:00h
Você mencionou o curso da Udemy. Segui o link e examinei o conteúdo de um trecho de uma das aulas de C, que estava com acesso público, como um tipo de degustação. Fiquei um tanto assustado com a quantidade de bobagens ditas no vídeo e escritas como código em C por parte do instrutor. Pelo tanto de propaganda da Udemy que já recebi, sinceramente esperava algo menos amador.
Agradeço suas informações. Realmente é difícil achar um curso descente na internet, principalmente nessas plataformas. O cara mal aprende algo e já sai dando curso e aí, uma pessoa que quer aprender como eu, acaba comprando um curso desses achando que o instrutor do curso entende de alguma coisa. Até o momento, não estou fazendo muita coisa em C, mas certamente estou aprimorando meus conhecimentos e aplicando práticas cada vez melhores em relação a qualquer linguagem de programação que eu for usar. Hoje, eu certamente procuro ser mais cauteloso em minhas publicações para garantir que eu não volte postar artigos ou dicas com conclusões equivocadas.
Tínhamos um pessoal com conhecimento legal na comunidade C / C++ do VoL não chegava a ser como um fórum do Stack Overflow, mas a gente (SamL, EnzoFerber, UilianRies, entre outros, além de mim) se esforçava. Infelizmente, acho que todos estamos com pouco tempo. De qualquer maneira, se quiser tirar dúvidas por lá, eu tento aparecer pelo menos umas duas vezes por semana.
[8] Comentário enviado por paulo1205 em 20/11/2021 - 20:47h
Agradeço suas informações. Realmente é difícil achar um curso descente na internet, principalmente nessas plataformas. O cara mal aprende algo e já sai dando curso e aí, uma pessoa que quer aprender como eu, acaba comprando um curso desses achando que o instrutor do curso entende de alguma coisa. Até o momento, não estou fazendo muita coisa em C, mas certamente estou aprimorando meus conhecimentos e aplicando práticas cada vez melhores em relação a qualquer linguagem de programação que eu for usar. Hoje, eu certamente procuro ser mais cauteloso em minhas publicações para garantir que eu não volte postar artigos ou dicas com conclusões equivocadas.
Tínhamos um pessoal com conhecimento legal na comunidade C / C++ do VoL não chegava a ser como um fórum do Stack Overflow, mas a gente (SamL, EnzoFerber, UilianRies, entre outros, além de mim) se esforçava. Infelizmente, acho que todos estamos com pouco tempo. De qualquer maneira, se quiser tirar dúvidas por lá, eu tento aparecer pelo menos umas duas vezes por semana.
Valeu. Entretanto, até o momento parti para o python, pretendo voltar a estudar mais o c/c++ em breve, aí tiro minhas dúvidas por lá.
Patrocínio

Destaques
Artigos
Instalar e Configurar o Slackware Linux em 2025
Como configurar os repositórios do apt no Debian 12 em 2025
Passkeys: A Evolução da Autenticação Digital
Instalação de distro Linux em computadores, netbooks, etc, em rede com o Clonezilla
Dicas
Como colorir os logs do terminal com ccze
Instalação Microsoft Edge no Linux Mint 22
Como configurar posicionamento e movimento de janelas no Lubuntu (Openbox) com atalhos de teclado
Máquinas Virtuais com IP estático acessando Internet no Virtualbox
Tópicos
Adapador Wi-Fi para de funcionar depois de alguns minutos no Ubuntu (1)
Compartilhando uma ideia sobre computação quantica (9)
Preciso atribuir um terceiro IP em uma placa de rede eth0. (7)
Top 10 do mês
-

Xerxes
1° lugar - 67.565 pts -

Fábio Berbert de Paula
2° lugar - 47.566 pts -

Mauricio Ferrari
3° lugar - 15.150 pts -

Buckminster
4° lugar - 14.335 pts -

Diego Mendes Rodrigues
5° lugar - 13.726 pts -

Daniel Lara Souza
6° lugar - 13.276 pts -

Alberto Federman Neto.
7° lugar - 12.824 pts -

Andre (pinduvoz)
8° lugar - 12.359 pts -

edps
9° lugar - 11.778 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
10° lugar - 10.756 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: