Tutorial hadoop - Guia prático de um cluster com 3 computadores
Seu chefe disse que para aumentar o lucro da empresa é necessário criar um buscador de site (ex.: Google), ou seja, fazer uma pesquisa de forma eficiente em um arquivo com 10GB de tamanho por exemplo. Então conheça na prática como a ferramenta hadoop pode lhe ajudar.
[ Hits: 36.333 ]
Por: Ronaldo Borges em 21/12/2015 | Blog: https://www.facebook.com/ronyjah1

Descrição
Descrição resumida das principais ferramentas de cluster hadoop:
O sistema hadoop realiza duas tarefas básicas, dividir o arquivo a ser computado entre os nodos usando um sistema de arquivo próprio (ferramenta HDFS) e a outra tarefa é executar a aplicação nos nodos (ferramenta MapReduce ou Yarn). Nesta primeira parte trataremos da configuração do serviço HDFS.
Recursos necessários para montar o cluster:
- 1x computador mestre para rodar o namenode*
- 2x computadores escravos para datanode**
Obs.: O sistema também funcionará apenas com dois computadores (um namenode e um datanode).
* namenode é o principal elemento do sistema de arquivos do cluster, é o gerenciador do sistema de arquivos, monitora a saúde dos computadores escravos (datanodes), medindo os recursos de disco rígido e memória disponível. Tem a função de fragmentar o metadado em blocos e repassar para os datanotes. Lembrando que para aumentar a robustez contra falha nos nodos, os blocos sao replicados por 3 (configuração padrão).
Obs.: nos meus testes eu deixei em torno de 10 GB disponíveis no HD. Se não configurado, o hadoop irá alocar automaticamente o espaço disponível no seu HD para montar o sistema de arquivo DFS.
** datanode - o sistema criado pelo namenode é chamado HDFS. Ele basicamente cria blocos de 128 MB (config default) entre os computadores datanode. Conforme o tamanho do metadado a ser processado, mais blocos serão criados. Para aumentar a robustez do sistema o namenode replicará os dados do metadado aos datanodes do cluster.
Na imagem abaixo é possível ver a ilustração de sistema de arquivos HDFS.
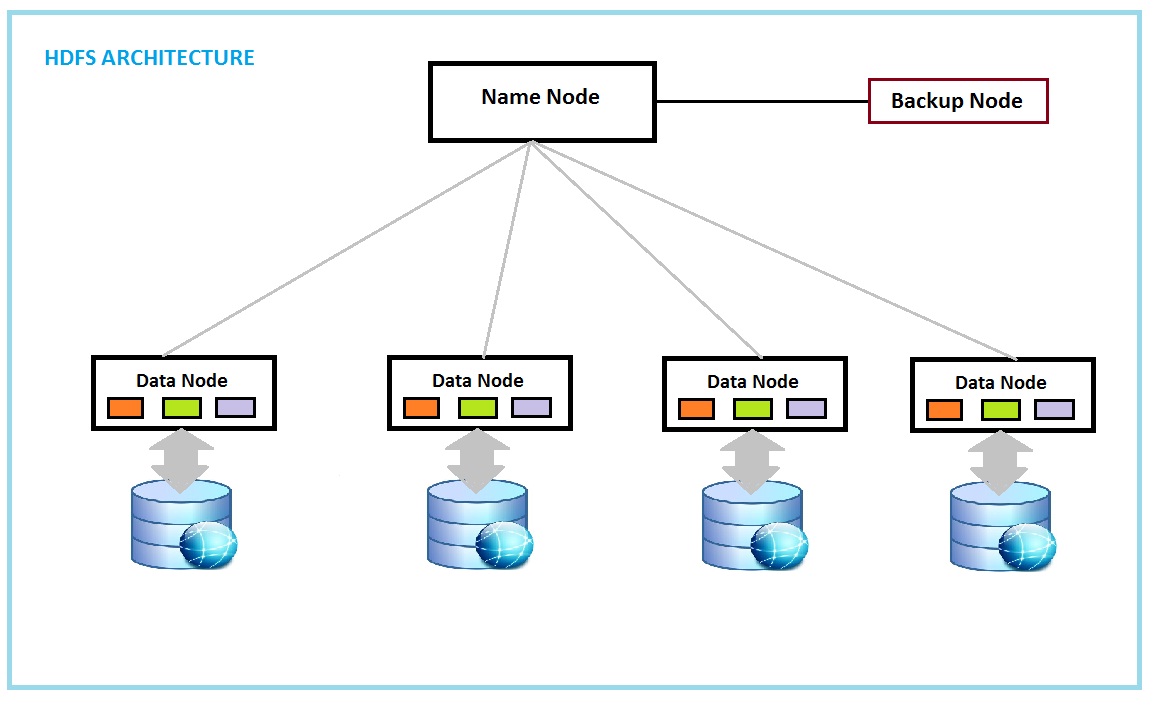
Este tutorial, foi implementado em sistema operacional Linux. Nas próximas paginas iremos descrever os principais componentes de configuração do cluster, arquivos de configuração, iniciação dos serviços e o exemplo de execução de uma aplicação contadora de palavras no cluster.
2. Configurando o ambiente nos computadores para receber o cluster hadoop
3. Instalação e configuração do hadoop
4. Iniciando o cluster hadoop
5. Testando o cluster Hadoop
6. Possíveis problemas
Tutorial - Aplicação em C para transferência de arquivo usando socket TCP e Thread
Configuração de serviço do Nagios para monitorar o APT do Ubuntu
Cliente Nagios no Windows - Instalação e Configuração
Balanceamento de links - Load balance + Failover + Failback
Importância do gerenciamento de redes e Nagios como ferramenta de gestão
Para fins de estudo e conhecimento o cenário proposto pelo artigo é valido. Em ambiente real não. Só pelo overhead gerado pelas tecnologias citadas mais a infraestrutura, a aplicação desta solução não vale a pena. O ecossistema Haddop deve preferencialmente ser usado quando REALMENTE o desafio de coleta, processamento e análise de dados demandam artilharia pesada! Deixo como sugestão a leitura desta apresentação e veja como problemas similares com um volume muito mais brutal de dados foram analisados usando apenas LINUX! http://slides.com/ronie/fbp_2015#/
[2] Comentário enviado por Lwkas em 28/12/2015 - 17:35h
Muito bom!
Fico agradecido por seu elogio, especialmente se este artigo for útil.
Cara, parabéns. Ótimo post de material riquíssimo.
Patrocínio

Destaques
Artigos
Enviar mensagem ao usuário trabalhando com as opções do php.ini
Meu Fork do Plugin de Integração do CVS para o KDevelop
Compartilhando a tela do Computador no Celular via Deskreen
Como Configurar um Túnel SSH Reverso para Acessar Sua Máquina Local a Partir de uma Máquina Remota
Configuração para desligamento automatizado de Computadores em um Ambiente Comercial
Dicas
Criando uma VPC na AWS via CLI
Multifuncional HP imprime mas não digitaliza
Dica básica para escrever um Artigo.
Como Exibir Imagens Aleatórias no Neofetch para Personalizar seu Terminal
Tópicos
Pegar a ultima ocorrencia viva (1)
Pq me aparece isso quando fui atualizar o Ubuntu 24.10 no terminal? (1)
como coloco para instalar com esse erro. (13)
Alguém sabe de documentos de texto e /ou vídeo aulas de certificações ... (1)
Top 10 do mês
-

Xerxes
1° lugar - 68.746 pts -

Fábio Berbert de Paula
2° lugar - 52.822 pts -

Buckminster
3° lugar - 19.552 pts -

Mauricio Ferrari
4° lugar - 16.267 pts -

Alberto Federman Neto.
5° lugar - 15.274 pts -

Daniel Lara Souza
6° lugar - 14.252 pts -

Diego Mendes Rodrigues
7° lugar - 13.926 pts -

edps
8° lugar - 11.850 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
9° lugar - 11.319 pts -

Andre (pinduvoz)
10° lugar - 11.087 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: