Como baixar o código HTML de um site por linha de comando no Linux
Dica publicada em Linux / Comandos

Como baixar o código HTML de um site por linha de comando no Linux
Olá meus Linuxers,
Na dica de hoje trago para vocês uma forma bem fácil de baixar o código HTML de um site sem usar nenhum tipo de software para isso, tudo via terminal!
Vamos lá.
Como exemplo vou usar o site da Google.
1 - Abra um emulador de terminal.
2 - Rode o seguinte comando:
wget -O html.txt https://www.google.com.br/
O resultado será semelhante ao da imagem baixo: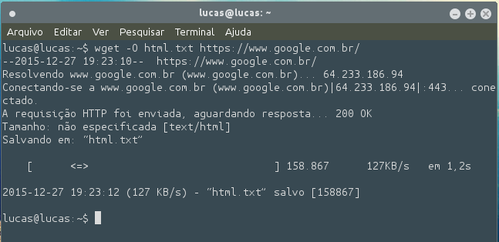 Em "wget -O" estamos dizendo ao terminal que queremos baixar um código HTML.
Em "wget -O" estamos dizendo ao terminal que queremos baixar um código HTML.
Em "html.txt" designamos o nome do arquivo onde sera salvo o código.
Em "https://www.google.com.br/" designamos o site que queremos o HTML.
3 - Agora basta acessar a pasta onde executaste o comando que o arquivo html.txt com o HTML do site vai estar lá, veja: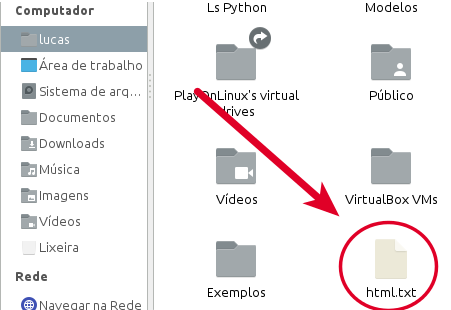 Abraço e até a próxima!
Abraço e até a próxima!
Na dica de hoje trago para vocês uma forma bem fácil de baixar o código HTML de um site sem usar nenhum tipo de software para isso, tudo via terminal!
Vamos lá.
Como exemplo vou usar o site da Google.
1 - Abra um emulador de terminal.
2 - Rode o seguinte comando:
wget -O html.txt https://www.google.com.br/
O resultado será semelhante ao da imagem baixo:

Em "html.txt" designamos o nome do arquivo onde sera salvo o código.
Em "https://www.google.com.br/" designamos o site que queremos o HTML.
3 - Agora basta acessar a pasta onde executaste o comando que o arquivo html.txt com o HTML do site vai estar lá, veja:

Pelo que eu conheço de programação, usando a flag -O renomeia para o nome especificado após ele, no caso do seu exemplo, html.txt. Se não usar a flag e nem o nome, será baixado com o nome do arquivo no servidor [creio eu], que geralmente é index.html
Espero ter ajudado
[]'s
T+
--
Att,
Thiago Henrique Hüpner
(Mensagem scaneada pelo antivírus........ops! não precisa, afinal eu uso Linux!)