Remover o ultimo caracter da ultima linha de uma determinada consulta.
13. Re: Remover o ultimo caracter da ultima linha de uma determinada consulta.

rhuan-pk
(usa Ubuntu)
Enviado em 28/07/2022 - 16:13h
hugoccgomes escreveu:
Boa tarde Pessoal.
Sou novo no shell e estou com dificuldade para eliminar o ultimo caracter da ultima linha em uma determinada consulta, como demonstrado abaixo:
1234567890,
0987654321,
3215465488,
Quero eliminar apenas a ultima virgula da ultima linha, sendo que independente do resulrados e quantidade de linhas que a consulta traga, preciso eliminar apenas o ultimo caracter.
1234567890,
0987654321,
3215465488
Grato pela atenção.
Boa tarde Pessoal.
Sou novo no shell e estou com dificuldade para eliminar o ultimo caracter da ultima linha em uma determinada consulta, como demonstrado abaixo:
1234567890,
0987654321,
3215465488,
Quero eliminar apenas a ultima virgula da ultima linha, sendo que independente do resulrados e quantidade de linhas que a consulta traga, preciso eliminar apenas o ultimo caracter.
1234567890,
0987654321,
3215465488
Grato pela atenção.
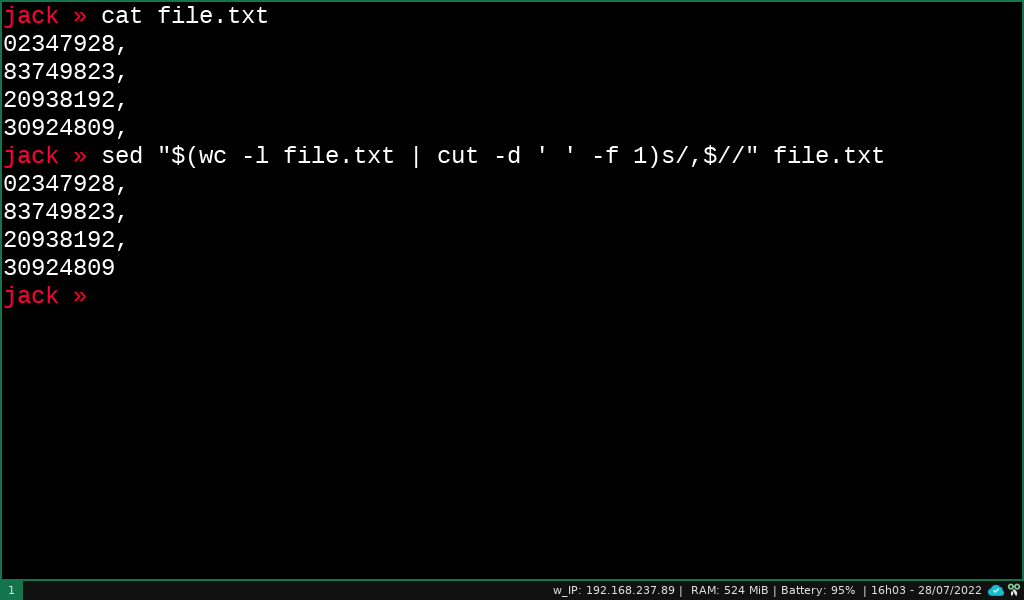
Eu pensei em algo um pouquinho diferente, faz a alteração somente na linha desejada, que no caso é a última... o comando wc com a opção -l vai trazer o número total de linha, logo o valor total de linhas é por acaso a última linha também...:
sed "$(wc -l file.txt | cut -d ' ' -f 1)s/,$//" file.txt
OBS: O comando wc -l, além do número total de linhas, traz o nome do arquivo, por isso que usamos o comando cut pra pegar só a primeira coluna (sendo o delimitador um único backspace)
Edit 1: Comando depois da sujestão do @msoliver
sed "$(wc -l < file.txt)s/,$//" file.txt
Edit 2: Não esqueça de usar a opção -i no sed caso queira persistir a informação.
Segue print de exemplo: