Entendendo os codecs, os containers formats e por que o Ogg é tão bom
Este artigo explica o que são e como funcionam os codecs, os formatos recipientes (conhecidos também como container formats) e os ótimos recursos do Ogg. Tudo com ótimos exemplos e ilustrações.
Os codecs e o Container Format - a explicação
Se você já sabe o que são codecs, formatos recipientes e outras noções básicas sobre arquivos digitais, então provavelmente não precisará ler esta página.
Quando você vê uma imagem no computador, é uma ilusão gerada pelo cérebro, que não percebe as imperfeições escondidas na tela do monitor. O monitor mostra um monte de pontos quadrados, cada um com uma cor diferente, mas os pontos são tão pequenos que o cérebro não percebe a ilusão por completo (você provavelmente tem dois olhos e graças a isso tem a noção de profundidade). A ilusão de movimento é gerada pela sequência de imagens, que têm um intervalo de tempo entre uma imagem e outra tão curto, que o cérebro não percebe a ilusão de movimento (mas dessa vez não percebe nenhuma parte da ilusão).
Certo, agora que você já sabe disso, precisa (caso ainda não tenha) de outra explicação. O computador armazena as informações agrupando bits. Os bits são os algarismos. Algumas pessoas não sabem a diferença, na matemática, entre algarismo e número mesmo depois de terminar a universidade (às vezes de matemática), então vou explicar isso também.
2520 é um número, com quatro algarismos. 2 e 64 são dois números, sendo que 2 é formado por um algarismo e 64 é formado por dois algarismos. Os bits também são algarismo, mas são algarismos de números do sistema numérico binário, isso significa que em vez de contar "1, 2, 3, 4, 5, 6, 7, ..." você conta (no sistema numérico binário) "1, 10 , 11, 100, 101, 110, 111, 1000, ...". Sendo assim o bit pode ser 1 ou 0.
Os bytes são o conjunto de 8 bits. Dois bytes formam um valor que, consultando uma tabela, simboliza uma letra. Quanto mais bits houver, mais espaço o arquivo vai ocupar no HD (ou outro dispositivo de armazenamento). Agora que você já entendeu o básico sobre como o computador armazena os arquivos, prossigamos com a explicação.
Imagine o gráfico de uma função. Agora imagine que um arquivo armazena cada ponto do gráfico. Esse arquivo é grande, mas o computador não precisa calcular onde estão os pontos da equação. Agora imagine outro arquivo que representa a mesma função, porém, em vez de armazenar cada ponto da equação, ele armazena a equação (ou equações, dependendo da complexidade do que você imaginou) do gráfico. O segundo arquivo é muito menor, porém pode demorar um pouco mais para abrir, pois a máquina irá precisar calcular as retas (ou círculos) da equação. Você acaba de entender os CODECS, mas além destas técnicas, há outras técnicas para comprimir arquivos.
A palavra codec vem de (en)COder e DECoder, que significam, respectivamente, codificador e decodificador. Eles são usados para codificar e comprimir vídeos e áudio digitais e decodificá-los também. Há três principais tipos de codecs:
Apesar de haver três tipos de codecs eles são geralmente agrupados em lossy (com perda de informações) e lossless (sem perda de informações). Agora vamos a explicação de formato recipiente.
Os codecs (principalmente os mais complexos) geram muitas informações e isso tudo fica agrupado nos arquivos, mas como separar estas informações estando elas todas no mesmo arquivo? O formato recipiente é um tipo de arquivo que armazena os bytes gerados pelos codecs e outras informações que são necessárias para decodificá-los (como resolução, taxa de frames por segundo, nome do vídeo/áudio/artista, taxa de bits por segundo, qual codec deve ser utilizado para decodificá-lo, entre outros). Eles funciona assim:
O arquivo é separado em várias partes. Os primeiros n bytes do arquivo formam a parte chamada de HEADER (que significa cabeça em inglês) e serve para identificar o arquivo. Nesta parte os primeiros y bytes podem identificar o tipo de arquivo recipiente, assim, mesmo que a extensão do arquivo esteja errada, o reprodutor multimídia ainda poderá ler o arquivo. Depois disso há bytes de tamanho fixos que informam por quantas partes o arquivo é formado e qual codec deve ser utilizado para decodificar cada parte.
As outras partes são formadas por um SUBHEADER, que identifica a parte e tem informações como "o tamanho da parte", "a resolução do vídeo (caso esta parte armazene um vídeo), entre outros e também por BODYs (que significa corpo em inglês), que são o conteúdo descrito pela HEADER e SUBHEADER. Mas há outros nomes para BODY como Ogg pages nos recipientes Ogg e chunk em alguns dos outros. Se algum HEADER (ou identificador) principal for danificado, o arquivo provavelmente não poderá ser decodificado (ou será decodificado erroneamente).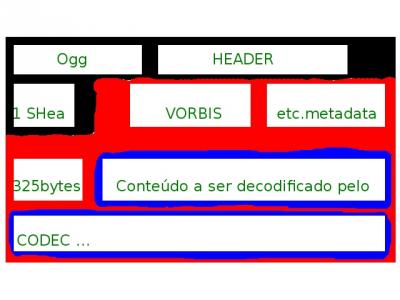 Na imagem anterior vocês podem perceber que a HEADER é "Ogg" e nela há a informação de que o arquivo guarda um SUBHEADER. A SUBHEADER identifica que o codec utilizado deve ser o vorbis e que os próximos 325 bytes fazem parte do BODY e, consequentemente, é o conteúdo a ser decodificado. Assim, há partes no codec que ocupam sempre o mesmo espaço e as partes que ocupam espaço variável (BODY) tem seu tamanho defino pelas HEADERs e/ou SUBHEADERs (depende do formato recipiente).
Na imagem anterior vocês podem perceber que a HEADER é "Ogg" e nela há a informação de que o arquivo guarda um SUBHEADER. A SUBHEADER identifica que o codec utilizado deve ser o vorbis e que os próximos 325 bytes fazem parte do BODY e, consequentemente, é o conteúdo a ser decodificado. Assim, há partes no codec que ocupam sempre o mesmo espaço e as partes que ocupam espaço variável (BODY) tem seu tamanho defino pelas HEADERs e/ou SUBHEADERs (depende do formato recipiente).
Há dois tipos principais de formatos recipientes e eles tem propósitos diferentes:
Quando você vê uma imagem no computador, é uma ilusão gerada pelo cérebro, que não percebe as imperfeições escondidas na tela do monitor. O monitor mostra um monte de pontos quadrados, cada um com uma cor diferente, mas os pontos são tão pequenos que o cérebro não percebe a ilusão por completo (você provavelmente tem dois olhos e graças a isso tem a noção de profundidade). A ilusão de movimento é gerada pela sequência de imagens, que têm um intervalo de tempo entre uma imagem e outra tão curto, que o cérebro não percebe a ilusão de movimento (mas dessa vez não percebe nenhuma parte da ilusão).
Certo, agora que você já sabe disso, precisa (caso ainda não tenha) de outra explicação. O computador armazena as informações agrupando bits. Os bits são os algarismos. Algumas pessoas não sabem a diferença, na matemática, entre algarismo e número mesmo depois de terminar a universidade (às vezes de matemática), então vou explicar isso também.
2520 é um número, com quatro algarismos. 2 e 64 são dois números, sendo que 2 é formado por um algarismo e 64 é formado por dois algarismos. Os bits também são algarismo, mas são algarismos de números do sistema numérico binário, isso significa que em vez de contar "1, 2, 3, 4, 5, 6, 7, ..." você conta (no sistema numérico binário) "1, 10 , 11, 100, 101, 110, 111, 1000, ...". Sendo assim o bit pode ser 1 ou 0.
Os bytes são o conjunto de 8 bits. Dois bytes formam um valor que, consultando uma tabela, simboliza uma letra. Quanto mais bits houver, mais espaço o arquivo vai ocupar no HD (ou outro dispositivo de armazenamento). Agora que você já entendeu o básico sobre como o computador armazena os arquivos, prossigamos com a explicação.
Imagine o gráfico de uma função. Agora imagine que um arquivo armazena cada ponto do gráfico. Esse arquivo é grande, mas o computador não precisa calcular onde estão os pontos da equação. Agora imagine outro arquivo que representa a mesma função, porém, em vez de armazenar cada ponto da equação, ele armazena a equação (ou equações, dependendo da complexidade do que você imaginou) do gráfico. O segundo arquivo é muito menor, porém pode demorar um pouco mais para abrir, pois a máquina irá precisar calcular as retas (ou círculos) da equação. Você acaba de entender os CODECS, mas além destas técnicas, há outras técnicas para comprimir arquivos.
A palavra codec vem de (en)COder e DECoder, que significam, respectivamente, codificador e decodificador. Eles são usados para codificar e comprimir vídeos e áudio digitais e decodificá-los também. Há três principais tipos de codecs:
- Sem compressão: Nestes codecs as informações são armazenadas exatamente como são recebidas, então os arquivos gerados são bem grandes, pois não há compressão de informações. Algumas vantagens de codecs que não usam compressão de dados é que eles exigem pouco poder de processamento e são ótimos para edição. A principal desvantagem é que os arquivos gerados por estes codecs ocupam muito espaço.
- Compressão sem perdas: Com estes codecs é diferente. As informações são comprimidas (eliminando redundâncias, usando quantização e outras técnicas) e os arquivos gerados são bem menores do que os originais. Uma grande vantagem deles é que nenhuma informação é perdida, então quando você quiser usar outro codec a qualidade será preservada, pois a informação processada pelo decodificador é a mesma recebida pelo codificador.
- Compressão com perdas: Neste tipo de codec parte das informações recebidas pelo codificador são descartadas para diminuir o tamanho do arquivo. Então você talvez pense "Mentira! Outro dia alguém me enviou uma foto no formato JPEG (onde há perda de informações) e a foto está perfeita". Bons codificadores descartam informações que geralmente não são percebidas pelos sentidos humanos (em fotos JPEG, as cores descartadas, são aquelas que estão MUITO próximas e são MUITO parecidas). Estes são os codecs mais utilizados hoje, mas não são muito usados por aqueles (como eu) obcecados por qualidade. Os arquivos gerados por estes codecs são geralmente os menores e o poder de processamento requerido é quase sempre maior que os requeridos pelos codecs sem-compressão. Quando o codec é muito complexo, chega a necessitar mais poder de processamento que os codecs onde há compressão sem perdas.
Apesar de haver três tipos de codecs eles são geralmente agrupados em lossy (com perda de informações) e lossless (sem perda de informações). Agora vamos a explicação de formato recipiente.
Os codecs (principalmente os mais complexos) geram muitas informações e isso tudo fica agrupado nos arquivos, mas como separar estas informações estando elas todas no mesmo arquivo? O formato recipiente é um tipo de arquivo que armazena os bytes gerados pelos codecs e outras informações que são necessárias para decodificá-los (como resolução, taxa de frames por segundo, nome do vídeo/áudio/artista, taxa de bits por segundo, qual codec deve ser utilizado para decodificá-lo, entre outros). Eles funciona assim:
O arquivo é separado em várias partes. Os primeiros n bytes do arquivo formam a parte chamada de HEADER (que significa cabeça em inglês) e serve para identificar o arquivo. Nesta parte os primeiros y bytes podem identificar o tipo de arquivo recipiente, assim, mesmo que a extensão do arquivo esteja errada, o reprodutor multimídia ainda poderá ler o arquivo. Depois disso há bytes de tamanho fixos que informam por quantas partes o arquivo é formado e qual codec deve ser utilizado para decodificar cada parte.
As outras partes são formadas por um SUBHEADER, que identifica a parte e tem informações como "o tamanho da parte", "a resolução do vídeo (caso esta parte armazene um vídeo), entre outros e também por BODYs (que significa corpo em inglês), que são o conteúdo descrito pela HEADER e SUBHEADER. Mas há outros nomes para BODY como Ogg pages nos recipientes Ogg e chunk em alguns dos outros. Se algum HEADER (ou identificador) principal for danificado, o arquivo provavelmente não poderá ser decodificado (ou será decodificado erroneamente).
Há dois tipos principais de formatos recipientes e eles tem propósitos diferentes:
- Sem intervalo: Este é o tipo de codec onde o BODY não é cortado, ele ocupa um espaço contínuo. Este tipo de formato recipiente costuma ter poucas subheaders e, por consequência, ocupar um pouco menos de espaço em disco, além de serem menos complexos. Costumam ser utilizados para reprodução local e como formato de edição. Exemplo:
O problema com os formatos recipientes sem intervalo é com os vídeos que devem ser distribuídos na internet. Imagine se os vídeos armazenados no YouTube usassem um formato recipiente sem intervalos. O navegador começaria a carregar uma das faixas (áudio OU vídeo) e só passaria a exibir a faixa seguinte após carregar completamente esta faixa.
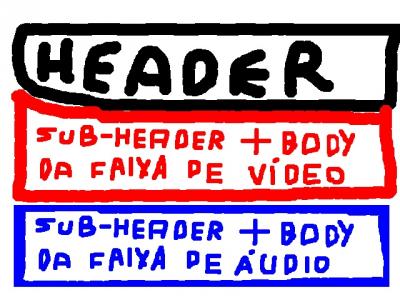
Então se a faixa que viesse primeiro fosse a de vídeo, você poderia assistir a faixa de vídeo (que, obviamente, não armazena som) e, após seu carregamento, escutar a faixa de áudio a medida que ela é carregada. Ou poderia esperar o carregamento da faixa de vídeo por completo e então assistir o vídeo (com o áudio) a medida que a faixa de áudio é carregada/baixada.
Há este problema para distribuição via internet e você só pode ter uma prévia do vídeo após baixar grande parte dele. Foi por isso que surgiram os formatos recipientes com intervalos.
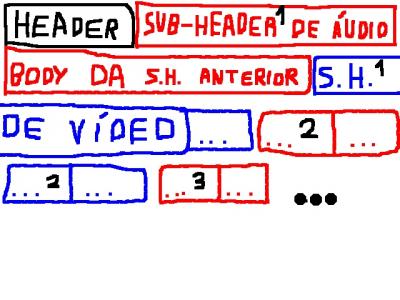
- Com intervalo: Nestes formatos recipientes as faixas (de áudio, vídeo, legendas e outros) são cortadas em pedaços menores e entrelaçadas para que o arquivo possa ser distribuída pela internet amigavelmente, pois cada parte do arquivo contém o vídeo, o áudio e/ou outras faixas. O arquivo abaixo demonstra resumidamente isso:


Gostei muito das informações sobre o OGG, não sabia que ele tinha tantas qualidades.
Procurei salvar minhas músicas em ogg.
Jairus Lopes