Linguagem C - Listas Duplamente Encadeadas
Neste artigo explicarei o que são listas duplamente encadeadas, como construí-las e suas vantagens e desvantagens. O pré-requisito para compreender bem o artigo é uma boa noção de ponteiros.
[ Hits: 110.968 ]
Por: Enzo de Brito Ferber em 07/01/2009 | Blog: http://www.maximasonorizacao.com.br

Introdução
int vetor[10];
O código acima declara um vetor com 10 elementos do tipo int. Podemos imaginar que ele está organizado na memória da seguinte forma:

Muito bom, com certeza. Saber onde estão nossas informações torna o acesso a elas muito eficiente. Mas, e se precisarmos armazenar informações em um ambiente cuja memória disponível seja esparsa? Em outras palavras, e se não houver espaço suficiente para alocar 10 elementos seguidos para nosso vetor? Então temos um problema.
Para solucionar esse problema, existe uma abstração de dados chamada "Lista Duplamente Encadeada". Existem também outros tipos de abstrações com o mesmo fim, que irão divergir em tempos de pesquisa, inserção, remoção, armazenagem, complexidade etc. Os cientistas da computação estão constantemente pesquisando novos algoritmos para implementações mais rápidas, ou menores, ou menos complexas, ou tudo isso ao mesmo tempo. Exemplos comuns são as listas encadeadas, árvores binárias e árvores binárias balanceadas (AVL ou RedBlack).
Cada uma dessas abstrações tem suas vantagens e desvantagens:
As listas encadeadas são extremamente eficientes (simples ou duplas), mas possuem tempo de pesquisa bem limitado - no pior caso, você precisa verificar todos os elementos para achar o que procura. Já as árvores binárias são estruturas de dados recursivas que oferecem um tempo de busca excepcional. Se uma árvore binária possui 1024 elementos, no pior caso da pesquisa serão 10 comparações para achar um elemento (em uma lista, seriam 1024 comparações).
O problema é que a implementação de árvores binárias é bem mais complexa que a implementação das listas encadeadas (até por sua natureza recursiva). Existe um outro problema com árvores binárias decorrente da forma com que o usuário insere os dados nela e chama-se degeneração em lista encadeada: se você inserir elementos de forma sequencial em uma árvore binária (1,2,3,4..), ela se "degenera" em uma lista encadeada, e perde sua propriedade de oferecer buscas eficientes.
Para resolver esse problema de degeneração, foram criados outros algoritmos (mais complexos) para balancear as árvores cada vez que um elemento é inserido e removido. Isso coloca as árvores binárias auto balanceáveis entre as estruturas de dados mais complexas que temos. Também torna o tempo de inserção um pouco maior, mas garante que a busca pela informação será excepcionalmente rápida. Ou seja, estamos sempre brincando com espaço de armazenagem, processamento e complexidade. Mas estes são temas para outros artigos.
Voltando às listas duplamente encadeadas:
struct LDE {
int info;
struct LDE *proximo;
struct LDE *anterior;
};
Acima, define-se a estrutura LDE - nosso bloco básico de construção da lista duplamente encadeada. Além da(s) informação(s) que queremos armazenar, faz-se necessário mais dois elementos na estrutura: dois ponteiros, um para o próximo elemento da lista e um para o elemento imediatamente anterior. Pode-se concluir que o espaço gasto para armazenar cada elemento é maior, mas a flexibilidade fornecida pelos ponteiros vale a pena.
Em uma arquitetura 32 bits, cada ponteiro ocupa 4 bytes. Já em 64 bits, cada ponteiro irá ocupar 8 bytes. Se um int possui tamanho 4 bytes, e esta estrutura for implementada em um processador 64 bits, cada elemento da nossalista ocupará 4 + 8 + 8 bytes = 20 bytes. Um simples sizeof() mostrará o tamanho da estrutura...
struct LDE {
int info;
struct LDE *proximo;
struct LDE *anterior;
};
int main (void)
{
printf ("%d\n", sizeof(struct LDE));
return 0;
}
Se você rodou o programa acima, viu que imprimiu 24 ao invés de 20 (64 bits). Se você alterar o programa acima para imprimir o tamanho de um int, e o tamanho de um ponteiro (64 bits), verá que o int terá 4 bytes, e cada ponteiro 8 bytes.
Então porquê o programa está mostrando 24 bytes? Alinhamento de memória.
Ponteiros são alinhados na memória automaticamente pelo compilador - isso se deve ao fato da natureza do acesso a memória dos registradores da CPU, mas isso é tema de ainda outro artigo... O importante é saber que a estrutura ocupa mais espaço que um simples elo de informação em um vetor mas que esse espaço vale cada bit a mais pela flexibilidade que os ponteiros vão nos fornecer para criar a abstração ilustrada na figura seguinte:
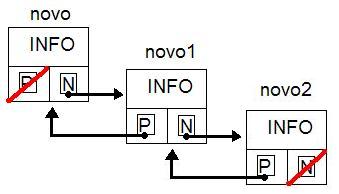
Agora que sabemos o motivo pelo qual utilizar uma lista duplamente encadeada, ou qualquer outro tipo de dados abstrato, vamos à implementação em si.
(A implementação mostrada neste artigo é bem simples, existem implementações muito mais complexas e robustas).
2. Listas encadeadas
3. Inserindo dados
4. Pesquisando
5. Removendo dados
6. Código completo
7. Conclusão
Linguagem C - Árvores Binárias
Linguagem C - Funções Variádicas
Análise dos Métodos de Ordenação usados em Algoritmos Computacionais
Linguagem C - Árvores Binárias
struct LDE
{
int info;
struct LDE *prox;
struct LDE *ante;
};
Não ocupa 12 bytes?
Você está enganado!
Toda a vez que for criado um elemento desta estrutura, ela ocupará UM espaço para um inteiro e DOIS espaços para ponteiros.
Se considerar o GCC 32 bits, ambos, inteiro e ponteiro, tem 4 bytes. Logo, NESTE CASO, Gcc32 bits, a estrutura ocupará SIM 12 bytes de tamanho.
Para 10 elementos de vetores de inteiros se ocupará exatos 40 bytes (em archs e compiladores 32 bits).
Se for uma lista encadeada dos mesmos 10 elementos, se ocupará 120 bytes (10x o tamanho de uma estrutura e cada estrutura ocupa 4 bytes para o info, 4 bytes para o ponteiro prox e 4 bytes para o ponteiro ante).
As vantagens/desvantagens de uma lista encadeada não tem a ver com economia de espaço, mas sim com a flexibilidade. Uma lista encadeada pode crescer até o limite de memória disponível e sempre eu posso "alocar mais um". Um vetor eu preciso previamente decidir o tamanho. Se 10, serão 10 e ponto! Precisei de 11? Não dá para aumentar o vetor em tempo de execução (ops, até dá com realloc, mas ai e outro tiro no pé).
Outra vantagem das listas encadeadas é a possibilidade de inserir ordenado ou remover no meio. Imagine um vetor de 15000 posições, 10mil delas ocupadas (de 0 a 9999). Ele está ORDENADO e preciso inserir o valor X que pela ordenanação ele deve ser inserido em vet[15]. Como é vetor, eu preciso:
(a) mover [9999] para [10000], [998] para [999], ..., [15] para [16] para inserir o novo elemento em [15].
(b) ou inserir no final [10000] e executar algum algoritmo de ordenamento como o quick sort
Se for lista encadeada, basta inserir na posição e ajustar os ponteiros ante e prox corretamente.
Listas encadeadas e suas derivações (duplamente, circular, com header, etc) são estrutura de dados muito úties, resolvem um monte de problemas, mas em comparação com vetores simples são mais complicados de manipular e consomem mais memória por elemento SIM.
Sobre tamanhos de tipos.
Como exemplo ao que disse anteriormente, o tamanho dos dados varia de acordo com a arquitetura. Ponteiro para qualquer coisa tem sempre o mesmo tamanho (isto é, não será maior se for ponteiro para double), mas não é certo dizer que o tamanho dele é 4 bytes. Isto é verdade apenas para arquiteturas e COMPILADORES de 32 bits, onde o endereçamento é por 32 bits e um inteiros também o é!
Mas em uma arquiteutra de 64 bits, com kernel e compilador 64 bits, será diferente.
Coloquei em minha página um código simples para obter o tamanho de cada dado, dependendo da estrutura (o mais comum é 32 bits, mas se alguem tiver um Linux de 64 bits, vai poder comprovar o que estou dizendo).
http://gravatai.ulbra.tche.br/~elgio/disciplinas/?DISC=outras&MAT=VOL
(veja o "Codigo simples para imprimir tamanhos de dados")
@ elgio
Obrigado pelos comentários antes de mais nada ;)
Desculpe o equívoco, li uma vez sobre isso (tamanho por elemento), e também achei plausível (já que o sizeof() mostrou isso...). Obrigado por colaborar e mostrar que eu estava enganado! ;)
Agora, quanto a inserção em vetores: não mencionei no artigo nada sobre isso, tudo isso é pré-requisito. As vantagens que você citou no comentário acho que estão subentendidas nas funções que mostrei... Se quem estiver lendo souber sobre vetores e conseguir entender o codigo, vai perceber tudo o que você falou, então achei irrelevante colocar...
Sempre fui péssimo para ensinar, mas já que não tinha nenhum artigo sobre Listas aqui no VOL, decidi fazer um, é vivendo e aprendendo! ;)
Agora uma pergunta: você notou que não coloquei nenhuma função para desalocar a lista no final do programa certo? Uma vez perguntei em uma comunidade de programação em linux se era necessário fazer tal função, me responderam que era por uma questão de estilo, mas que o sistema operacional faria isso mesmo sem minha função. Esta informação esta correta?
[]'s
Slackware_10
Hmm, vi seu código, sei disso.
Sei que os ponteiros ocupam espaço, só que sempre achei (desde que li sobre) que quando você atribuía endereços eles "passavam a ser" o elemento (como disse no artigo), sendo assim, paravam de ocupar o espaço do ponteiro propriamente dito e passavam a ocupar o espaço do elemento a qual foram atribuídos. E é por isso que coloquei o sizeof(novo1) por exemplo, mesmo com os 2 ponteiros não nulos presentes, a estrutura continua a apresentar tamanho 4 bytes. Isso achei estranho, deve ser bug da função :P
E sim, agora vendo o que você falou, vejo que o tamanho é realmente 12 bytes por uma única coisa:
struct LDE *novo = MALLOC(struct LDE);
Isso vai alocar sizeof(struct LDE) de memória, e esse tamanho é 12. Sim, coloquei uma informação errada no artigo. :(
Mais deu pra entender o porque eu assumi isso? sizeof() maledito!
Obrigado pela colaboraçao mais uma vez.
[]'s
Slackware_10
Sobre DESALOCAR espaço, não é uma questão de estilo.
Isto é uma das coisas que fazem parte do que chamo "Manual do bom programador", entre outras:
a) sempre testar se realmente alocou
b) sempre testar arquivos
c) sempre fechar arquivos.
eu EXIJO isto dos meus alunos!
Explicando melhor...
Seu amigo está certo ao dizer que o Sistema Operacional desaloca tudo, fecha tudo, limpa e deixa a casa em ordem quando o seu programa encerra. Mas esquecer de fazer a limpeza pode trazer SÉRIOS PROBLEMAS.
Se o teu programa é do tipo que inicia, faz algo e termina, OK. É desnecessário este cuidado.
Mas se tu estiver programando algo que nunca termina? Um serviço do SO, por exemplo, como um servidor http? Hmmm...
Se tu fica alocando, alocando, alocando e nunca desaloca, chegará um ponto que não terás mais memória. O servidor apache teve um BUG deste tipo certa vez. Era necessário reinicar ele periodicamente para ele "se limpar" :-D
O mesmo para arquivos abertos. Se abriu, usou, FECHA! Mas o So não fecha automaticamente? Sim, quando o programa encerrar e SE ENCERRAR CORRETAMENTE! (um kill -9 poderá resultar em perdas de dados).
Logo, nada melhor do que se acostumar a fazer do jeito certo, o jeito que sempre funciona, seguindo o que chamo de manual do bom programador:
- alocou? desaloca
- abriu? fecha
- tentou alocar? testa se conseguiu.
- tentou abrir arquivo? testa se conseguiu.
SEMPRE!
Bom, tudo isso eu faço,
A única coisa que realmente não faço, é destruir a lista encadeada, pois o programa vai acabar, e desaloca apenas para deletar.
Mas vou passar a fazer isso. :)
Obrigado denovo!!!
[]'s
"E é por isso que coloquei o sizeof(novo1) por exemplo, mesmo com os 2 ponteiros não nulos presentes, a estrutura continua a apresentar tamanho 4 bytes. Isso achei estranho, deve ser bug da função :P"
Não é BUG.
Tem que entender o que realmente aconteceu.
novo, novo1 e novo2 NÃO SÃO ESTRUTURAS!
São ponteiros.
Seus conteúdos são endereços de memória, ou seja, para onde eles apontam. E será SEMPRE de 4 bytes (no caso de archs 32 bits) não importanto se para onde eles apontam tem um inteiro ou estrutura.
Veja este exemplo:
struct LIXO {
int d1, d2, d3; // 3x 4 = 12 bytes
double d4[10]; // 10x 8 bytes = 80 bytes
}
Bom, a estrutura terá 92 bytes (no mínimo! compiladores como o gcc sempre alocam multiplos de 8, podendo variar)
struct LIXO a; // isto é uma variável DO TIPO struct LIXO. Ocupará SIM 92 bytes
struct LIXO *p; // p NÃO É DO TIPO scruct LIXO. É do tipo PONTEIRO e ponteiros sempre tem 4 bytes. eles apontam para algo
printf("%d\n", sizeof(a)); // deverá imprimir no mínimo 92
printf("%d\n", sizeof(p)); // imprimirá 4 em 32 bits e 8 em 64 bits
}
To vendo se tenho algum exemplo já preparado para alunos para postar aqui.
Aaaaaaaaahhhhhhhhhh!
Nossa, agora eu me envergonhei, meu deus, cade o buraco pra eu enfiar a cabeça? auhauhauhauah
Como escrevi uma bobagem dessas no artigo?? o.O
Deve ser o tempo parado...
Bom, agora voltando à ativa e com pessoas colaborando as coisas vão melhorar....
Sinceramente, me desculpem.
Obrigado elgio,
[]'s
Slackware_10
???
Enzo...
Seria bom que você apagasse ou editasse o comentário acima.
Idiotisse? Asneira?
Só erra quem tenta. Teu artigo não está errado, apenas levemente incompleto e isto não lhe tira o mérito.
E se você olhar bem o meu perfil verás que eu só intervenho em artigos que valham a pena. Eu realmente não perco mais meu tempo comentando os artigos que eu realmente considere "idiotisse" :-D
Tudo bem, asneira e idiotice podem ter sido um pouco pesadas, mas acho que corretas, pois escrevi que uma boa noção de ponteiros seria necessária, e não foi isso que demonstrei ;)
Mas convenhamos, a primeira página do artigo poderia ser totalmente reformulada apresentando os conceitos que você expos aqui, por exemplo. Obrigado pelo apoio,
[]'s
Slackware_10
Parabéns pelo artigo. Apesar dos pequenos erros (eu só me apercebi pelos pertinentes comentários do elgio), o artigo está bastante bom e explica bastante bem os conceitos pretendidos. Os comentários apresentaram uma discussão interessante.
Parabéns pelo seu artigo, fora alguns detalhes, está bem completo! Agradeço também ao Elgio pelos complementos! É importante saber bem estes conceitos, principalmente para as aulas de Projetos de Sistemas Operacionais que deve ser lecionadas pelo Prof. Roland aí em Gravataí :) Um abraço! Alex.
Parabéns pelo artigo, Enzo.
Acredito que os erros apontados nos comentários são normais, afinal, todo mundo erra. Não seria interessante você escrever um artigo transformando esse seu programa de listas duplamente-encadeadas em uma biblioteca C (evitando o uso das variáveis globais inicio e fim, por exemplo, colocando funções que recebam as listas, criando um tipo para receber listas como variáveis e coisas do tipo) ou um artigo a respeito de árvores binárias balanceadas ou mesmo de outros tipos de estruturas em árvore?
Obrigado a todos pelos comentários, em especial ao Elgio, que me fez ver erros grosseiros que havia cometido na introdução do artigo. Esse ano (2015), entrei em contato com o Fábio (administrador do VoL) e expliquei a situação (artigo incorreto). Perguntei se havia algum modo de corrigi-lo e ele prontamente se dispôs a receber uma correção por email e fazer a atualização no site.
Hoje, 14 de abril de 2015, a página da introdução foi trocada por uma outra que contém informações corretas. Então, a todos que virem os comentários anteriores, trata-se de uma discussão sobre alguns conceitos errôneos da antiga "Introdução".
Obrigado Fábio, pela chance de consertar um erro e manter a qualidade do VoL.
Enzo Ferber
[]'s
Patrocínio

Destaques
Artigos
Passkeys: A Evolução da Autenticação Digital
Instalação de distro Linux em computadores, netbooks, etc, em rede com o Clonezilla
Título: Descobrindo o IP externo da VPN no Linux
Armazenando a senha de sua carteira Bitcoin de forma segura no Linux
Enviar mensagem ao usuário trabalhando com as opções do php.ini
Dicas
Como configurar posicionamento e movimento de janelas no Lubuntu (Openbox) com atalhos de teclado
Máquinas Virtuais com IP estático acessando Internet no Virtualbox
Instalar o Microsoft Edge no Slackware 15
Instalando Brave Browser no Linux Mint 22
vídeo pra quem quer saber como funciona Proteção de Memória:
Tópicos
Separar trafego da VPN da VPS (0)
Formatando cartão de memoria que nao formata[AJUDA] (17)
warsaw parou de funcionar após atualização do sistema (solução) (0)
Desde que seja DDR3, posso colocar qualquer memória? [RESOLVIDO] (6)
Top 10 do mês
-

Xerxes
1° lugar - 75.116 pts -

Fábio Berbert de Paula
2° lugar - 54.009 pts -

Mauricio Ferrari
3° lugar - 16.829 pts -

Andre (pinduvoz)
4° lugar - 15.936 pts -

Alberto Federman Neto.
5° lugar - 15.255 pts -

Daniel Lara Souza
6° lugar - 15.142 pts -

Diego Mendes Rodrigues
7° lugar - 15.036 pts -

Buckminster
8° lugar - 14.139 pts -

edps
9° lugar - 12.438 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
10° lugar - 11.781 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: