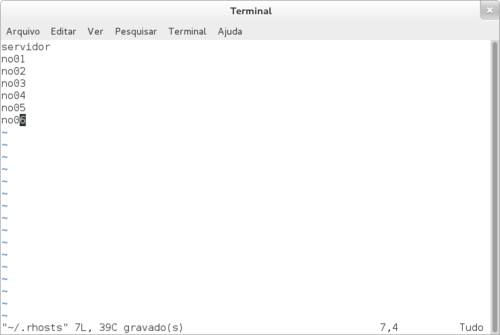
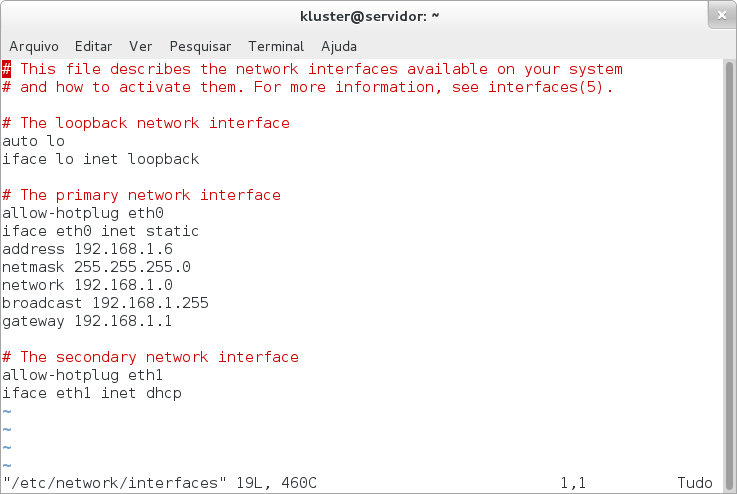
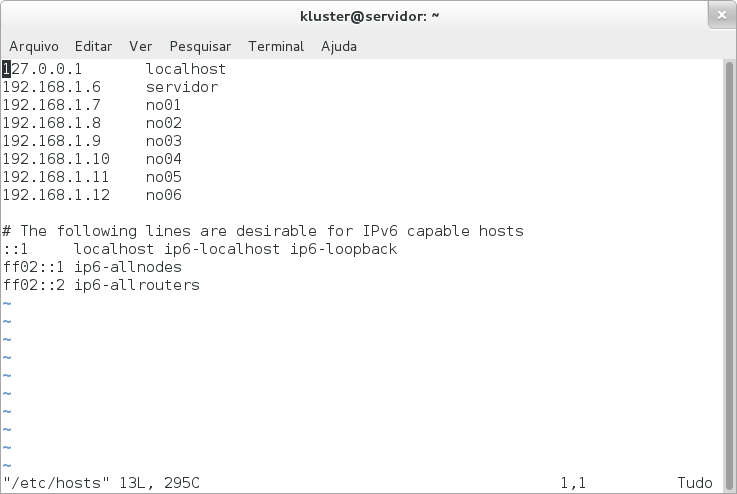
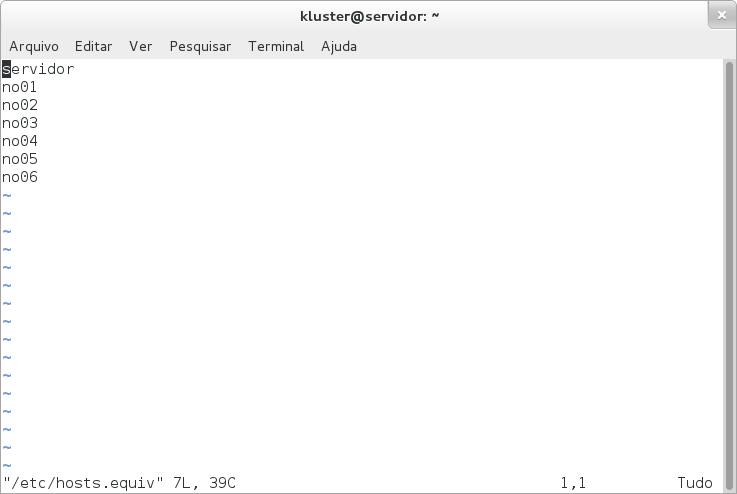
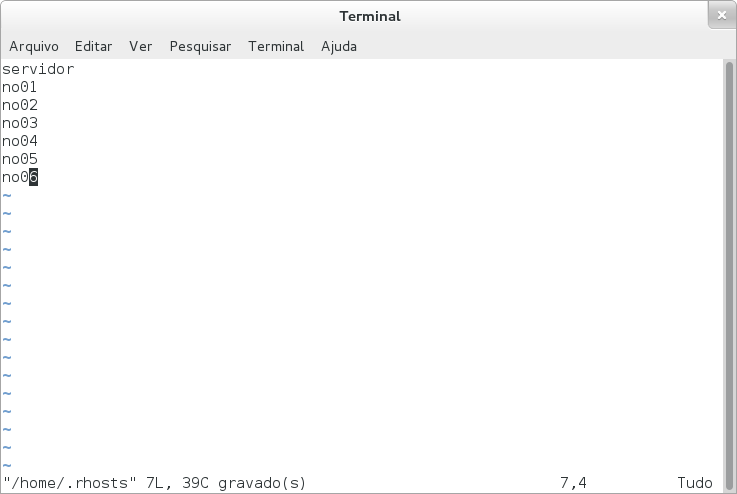
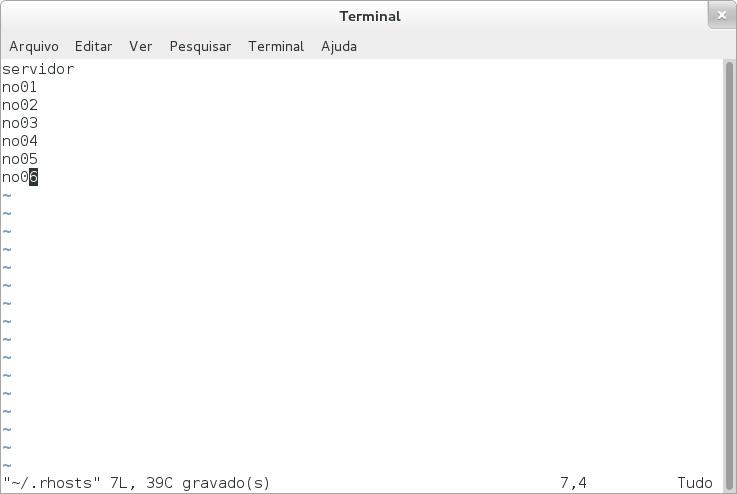
Obrigado por tirar essas dúvidas!
Então, o algoritmo é em C mesmo. Peguei dois algoritmos prontos na internet. O primeiro não lembro o link, mas o código fonte está aí:
/*
********************************************************************
Example 26 (gauss_elimination.c)
Objective : To solve the system of Linear Equations
using Gaussian Elimination without
pivoting on 'p' processors.
Input : Read files (mdatgaus.inp) for Matrix A
and (vdatgaus.inp) for Vector b
Output : The solution of matrix system of linear
equations Ax=b on processor 0.
Description : Input matrix is stored in n by n format.
Columnwise cyclic distribution of input
matrix is used for partitioning of the
matrix.
Necessary conditions : Number of Processes should be less than
or equal to 8.Matrix size for Matrix A
and vector size for vector b should be
equally striped, that is Matrix size and
Vector Size should be divisible by Number
of processes used.
********************************************************************
*/
#include <stdio.h>
#include <assert.h>
#include <mpi.h>
main(int argc, char** argv) {
/* .......Variables Initialisation ......*/
MPI_Status status;
int n_size, NoofRows_Bloc, NoofRows, NoofCols;
int Numprocs, MyRank, Root = 0;
int irow, jrow, icol, index, ColofPivot, neigh_proc;
double **Matrix_A, *Input_A, *Input_B, *ARecv, *BRecv;
double *Output, Pivot;
double *X_buffer, *Y_buffer;
double *Buffer_Pivot, *Buffer_bksub;
double tmp;
FILE *fp;
/* ........MPI Initialisation .......*/
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &MyRank);
MPI_Comm_size(MPI_COMM_WORLD, &Numprocs);
/* .......Read the Input file ......*/
if(MyRank == 0) {
if ((fp = fopen ("./data/mdatgaus.inp", "r")) == NULL) {
printf("Can't open input matrix file");
exit(-1);
}
fscanf(fp, "%d %d", &NoofRows,&NoofCols);
n_size=NoofRows;
/* ...Allocate memory and read data .....*/
Matrix_A = (double **) malloc(n_size*sizeof(double *));
for(irow = 0; irow < n_size; irow++){
Matrix_A[irow] = (double *) malloc(n_size * sizeof(double));
for(icol = 0; icol < n_size; icol++)
fscanf(fp, "%lf", &Matrix_A[irow][icol]);
}
fclose(fp);
if ((fp = fopen ("./data/vdatgaus.inp", "r")) == NULL){
printf("Can't open input vector file");
exit(-1);
}
fscanf(fp, "%d", &NoofRows);
n_size=NoofRows;
Input_B = (double *)malloc(n_size*sizeof(double));
for (irow = 0; irow<n_size; irow++)
fscanf(fp, "%lf",&Input_B[irow]);
fclose(fp);
/* ...Convert Matrix_A into 1-D array Input_A ......*/
Input_A = (double *)malloc(n_size*n_size*sizeof(double));
index = 0;
for(irow=0; irow<n_size; irow++)
for(icol=0; icol<n_size; icol++)
Input_A[index++] = Matrix_A[irow][icol];
}
MPI_Bcast(&NoofRows, 1, MPI_INT, Root, MPI_COMM_WORLD);
MPI_Bcast(&NoofCols, 1, MPI_INT, Root, MPI_COMM_WORLD);
if(NoofRows != NoofCols) {
MPI_Finalize();
if(MyRank == 0){
printf("Input Matrix Should Be Square Matrix ..... \n");
}
exit(-1);
}
/* .... Broad cast the size of the matrix to all ....*/
MPI_Bcast(&n_size, 1, MPI_INT, 0, MPI_COMM_WORLD);
if(n_size % Numprocs != 0) {
MPI_Finalize();
if(MyRank == 0){
printf("Matrix Can not be Striped Evenly ....No of processors (p) should divide the size of the Input matrix (n)\n");
}
exit(-1);
}
NoofRows_Bloc = n_size/Numprocs;
/*......Memory of input matrix and vector on each process .....*/
ARecv = (double *) malloc (NoofRows_Bloc * n_size* sizeof(double));
BRecv = (double *) malloc (NoofRows_Bloc * sizeof(double));
/*......Scatter the Input Data to all process ......*/
MPI_Scatter (Input_A, NoofRows_Bloc * n_size, MPI_DOUBLE, ARecv, NoofRows_Bloc * n_size,
MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Scatter (Input_B, NoofRows_Bloc, MPI_DOUBLE, BRecv, NoofRows_Bloc, MPI_DOUBLE, 0,
MPI_COMM_WORLD);
/* ....Memory allocation of ray Buffer_Pivot .....*/
Buffer_Pivot = (double *) malloc ((NoofRows_Bloc + 1 + n_size * NoofRows_Bloc) * sizeof(double));
/* Receive data from all processors (i=0 to k-1) above my processor (k).... */
for(neigh_proc = 0; neigh_proc < MyRank; neigh_proc++) {
MPI_Recv(Buffer_Pivot, NoofRows_Bloc * n_size + 1 + NoofRows_Bloc, MPI_DOUBLE, neigh_proc,
neigh_proc, MPI_COMM_WORLD, &status);
for(irow = 0; irow < NoofRows_Bloc; irow++){
/* .... Buffer_Pivot[0] : locate the rank of the processor received */
/* .... Index is used to reduce the matrix to traingular matrix */
/* .... Buffer_Pivot[0] is used to determine the starting value of
pivot in each row of the matrix, on each processor */
ColofPivot = ((int) Buffer_Pivot[0]) * NoofRows_Bloc + irow;
for (jrow = 0; jrow < NoofRows_Bloc; jrow++){
index = jrow*n_size;
tmp = ARecv[index + ColofPivot];
for (icol = ColofPivot; icol < n_size; icol++)
ARecv[index + icol] -= tmp * Buffer_Pivot[irow*n_size+icol+1+NoofRows_Bloc];
BRecv[jrow] -= tmp * Buffer_Pivot[1+irow];
ARecv[index + ColofPivot] = 0.0;
}
}
}
/* ......Buffer_bksuborary buffer allocation ....*/
Y_buffer = (double *) malloc (NoofRows_Bloc * sizeof(double));
/* ....Modification of row entries on each processor ...*/
/* ....Division by pivot value and modification ...*/
for(irow = 0; irow < NoofRows_Bloc; irow++){
ColofPivot = MyRank * NoofRows_Bloc + irow;
index = irow*n_size;
Pivot = ARecv[index + ColofPivot];
assert(Pivot!= 0);
for (icol = ColofPivot; icol < n_size; icol++){
ARecv[index + icol] = ARecv[index + icol]/Pivot;
Buffer_Pivot[index + icol + 1 + NoofRows_Bloc] = ARecv[index + icol];
}
Y_buffer[irow] = BRecv[irow] / Pivot;
Buffer_Pivot[irow+1] = Y_buffer[irow];
for (jrow = irow+1; jrow<NoofRows_Bloc; jrow++) {
tmp = ARecv[jrow*n_size + ColofPivot];
for (icol = ColofPivot+1; icol < n_size; icol++)
ARecv[jrow*n_size+icol] -= tmp * Buffer_Pivot[index + icol + 1 + NoofRows_Bloc];
BRecv[jrow] -= tmp * Y_buffer[irow];
ARecv[jrow*n_size+irow] = 0;
}
}
/*....Send data to all processors below the current processors */
for (neigh_proc = MyRank+1; neigh_proc < Numprocs; neigh_proc++) {
/* ...... Rank is stored in first location of Buffer_Pivot and
this is used in reduction to triangular form ....*/
Buffer_Pivot[0] = (double) MyRank;
MPI_Send(Buffer_Pivot, NoofRows_Bloc*n_size+1+NoofRows_Bloc, MPI_DOUBLE, neigh_proc,
MyRank, MPI_COMM_WORLD);
}
/*.... Back Substitution starts from here ........*/
/*.... Receive from all higher processors ......*/
Buffer_bksub = (double *) malloc (NoofRows_Bloc * 2 * sizeof(double));
X_buffer = (double *) malloc (NoofRows_Bloc * sizeof(double));
for (neigh_proc = MyRank+1; neigh_proc<Numprocs; ++neigh_proc) {
MPI_Recv(Buffer_bksub, 2*NoofRows_Bloc, MPI_DOUBLE, neigh_proc, neigh_proc,
MPI_COMM_WORLD,&status);
for (irow = NoofRows_Bloc-1; irow >= 0; irow--) {
for (icol = NoofRows_Bloc-1;icol >= 0; icol--) {
/* ... Pick up starting Index .....*/
index = (int) Buffer_bksub[icol];
Y_buffer[irow] -= Buffer_bksub[NoofRows_Bloc+icol] * ARecv[irow*n_size+index];
}
}
}
for (irow = NoofRows_Bloc-1; irow >= 0; irow--) {
index = MyRank*NoofRows_Bloc+irow;
Buffer_bksub[irow] = (double) index;
Buffer_bksub[NoofRows_Bloc+irow] = X_buffer[irow] = Y_buffer[irow];
for (jrow = irow-1; jrow >= 0; jrow--)
Y_buffer[jrow] -= X_buffer[irow] * ARecv[jrow*n_size + index];
}
/*.... Send to all lower processes...*/
for (neigh_proc = 0; neigh_proc < MyRank; neigh_proc++)
MPI_Send(Buffer_bksub, 2*NoofRows_Bloc, MPI_DOUBLE, neigh_proc, MyRank, MPI_COMM_WORLD);
/*.... Gather the result on the processor 0 ....*/
Output = (double *) malloc (n_size * sizeof(double));
MPI_Gather(X_buffer, NoofRows_Bloc, MPI_DOUBLE, Output, NoofRows_Bloc, MPI_DOUBLE, 0, MPI_COMM_WORLD);
/* .......Output vector .....*/
if (MyRank == 0) {
printf ("\n");
printf(" ------------------------------------------- \n");
printf("Results of Gaussian Elimination Method on processor %d: \n", MyRank);
printf ("\n");
printf("Matrix Input_A \n");
printf ("\n");
for (irow = 0; irow < n_size; irow++) {
for (icol = 0; icol < n_size; icol++)
printf("%.3lf ", Matrix_A[irow][icol]);
printf("\n");
}
printf ("\n");
printf("Matrix Input_B \n");
printf("\n");
for (irow = 0; irow < n_size; irow++) {
printf("%.3lf\n", Input_B[irow]);
}
printf ("\n");
printf("Solution vector \n");
printf ("\n");
for(irow = 0; irow < n_size; irow++)
printf("%.3lf\n",Output[irow]);
printf(" --------------------------------------------------- \n");
}
MPI_Finalize();
}
O segundo, tá nesse link
http://technolog-world.blogspot.com.br/2010/02/mpi-program-that-implements-gauss_07.html
Provavelmente vou usar o segundo mesmo, pois ele gera dois arquivos de saída e também tá melhor organizado IMHO.