Tutorial Kettle
O Kettle é uma ferramenta para integração de dados, responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações, exportação de banco para arquivos, limpeza de dados e na integração de aplicações.

Introdução
O Kettle é uma ferramenta para integração de dados, faz parte da solução Pentaho1, onde é responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações ou base de dados, exportação de dados de banco para arquivos, limpeza de dados e na integração de aplicações.
O primeiro passo para iniciar o uso da ferramenta Kettle é ter um conhecimento sobre o que é data warehouse ou DW, para simplificar. Estas informações estão distribuídas na internet ou em livros e são de suma importância para entender os conceitos básicos tais como Modelo Estrela, Dimensões, Fatos, ETL.
Este tutorial tem por objetivo auxiliar no uso inicial da ferramenta, ele contempla algumas das funções mais utilizadas no processo de ETL, além de algumas dicas para evitar "dores de cabeça" no uso da mesma. O conteúdo encontra-se distribuído de forma bem didática, direta e objetiva, sendo assim poupou-se muitos formalismos, ficando este para uma proposta futura de se publicar um manual ou artigo.
[1] http://www.pentaho.com
Uma transformação é uma rotina com uma coleção de passos interligados, dos quais o primeiro representa a fonte ou os dados e o último representa a saída dos dados.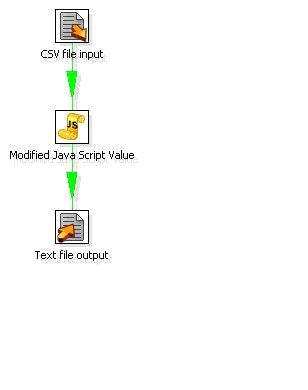 Em uma única transformação podem ser colocadas várias fontes de dados e várias saídas de dados, no caso de data warehouse o recomendado é utilizar uma transformação para cada dimensão ou tabela de fatos, no final isto ajuda na organização e na criação dos Jobs.
Em uma única transformação podem ser colocadas várias fontes de dados e várias saídas de dados, no caso de data warehouse o recomendado é utilizar uma transformação para cada dimensão ou tabela de fatos, no final isto ajuda na organização e na criação dos Jobs.
Jobs
Um Job é uma rotina de execução, onde pode executar uma ou mais transformações ou Jobs, além de diversas outras ações. Neste tutorial iremos retratar apenas Jobs para executar as transformações em conjunto, separadas em cargas de dimensões estáticas, dimensões de modificação lenta e carga dos fatos.
Step (Passo)
Um passo é uma unidade mínima dentro de uma Transformação. Uma grande variedade de passos encontra-se disponível e agrupada em categorias tais como Input e Output, entre outros. Fundamentalmente existem três tipos básicos de passos, que são os de entrada, transformação e saída.
Cada passo é modelado para atender uma função específica, tais como ler um parâmetro ou normalizar um grupo de dados. Os passos são facilmente criados utilizando o recurso de drag and drop (arrastar e largar).
Uma vez criado, para abrir, basta um duplo clique no ícone. Uma janela aparece, permitindo parametrizar o comportamento do mesmo. Muitos passos possuem múltiplas propriedades de acordo com a categoria que se encontra.
Recomenda-se fortemente que o passo seja renomeado, assim a função fica mais fácil de ser identificada no diagrama.
Hop
Um "hop" é uma representação gráfica do fluxo de dados entre dois passos (conexão), sendo um deles a origem e o outro o destino. Os dados que passam por um Hop constituem os dados de saída do passo de origem. Uma conexão pode ser criada clicando no passo de origem, pressionando o botão shift, e arrastar o mouse (mantendo o botão pressionado) até o passo destino.
O primeiro passo para iniciar o uso da ferramenta Kettle é ter um conhecimento sobre o que é data warehouse ou DW, para simplificar. Estas informações estão distribuídas na internet ou em livros e são de suma importância para entender os conceitos básicos tais como Modelo Estrela, Dimensões, Fatos, ETL.
Este tutorial tem por objetivo auxiliar no uso inicial da ferramenta, ele contempla algumas das funções mais utilizadas no processo de ETL, além de algumas dicas para evitar "dores de cabeça" no uso da mesma. O conteúdo encontra-se distribuído de forma bem didática, direta e objetiva, sendo assim poupou-se muitos formalismos, ficando este para uma proposta futura de se publicar um manual ou artigo.
[1] http://www.pentaho.com
Conceitos
TransformaçãoUma transformação é uma rotina com uma coleção de passos interligados, dos quais o primeiro representa a fonte ou os dados e o último representa a saída dos dados.

Jobs
Um Job é uma rotina de execução, onde pode executar uma ou mais transformações ou Jobs, além de diversas outras ações. Neste tutorial iremos retratar apenas Jobs para executar as transformações em conjunto, separadas em cargas de dimensões estáticas, dimensões de modificação lenta e carga dos fatos.
Step (Passo)
Um passo é uma unidade mínima dentro de uma Transformação. Uma grande variedade de passos encontra-se disponível e agrupada em categorias tais como Input e Output, entre outros. Fundamentalmente existem três tipos básicos de passos, que são os de entrada, transformação e saída.
Cada passo é modelado para atender uma função específica, tais como ler um parâmetro ou normalizar um grupo de dados. Os passos são facilmente criados utilizando o recurso de drag and drop (arrastar e largar).
Uma vez criado, para abrir, basta um duplo clique no ícone. Uma janela aparece, permitindo parametrizar o comportamento do mesmo. Muitos passos possuem múltiplas propriedades de acordo com a categoria que se encontra.
Recomenda-se fortemente que o passo seja renomeado, assim a função fica mais fácil de ser identificada no diagrama.
Hop
Um "hop" é uma representação gráfica do fluxo de dados entre dois passos (conexão), sendo um deles a origem e o outro o destino. Os dados que passam por um Hop constituem os dados de saída do passo de origem. Uma conexão pode ser criada clicando no passo de origem, pressionando o botão shift, e arrastar o mouse (mantendo o botão pressionado) até o passo destino.
Gostaria de parabenizá-lo pelo artigo. Parece ser uma ferramenta interessante, dado que para BI, conheço somente ferramentas pagas, não caras, mas pagas. Mas, como comentário, ficou faltando somente esclarecer um pouco mais, dado que é uma ferramenta de ETL, sobre as suas bases : Granularidade, Dimensões, Fatos... Bom, mas ficou muito bom.
Parabéns
Abraços