Tutorial Kettle
O Kettle é uma ferramenta para integração de dados, responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações, exportação de banco para arquivos, limpeza de dados e na integração de aplicações.

Parte 3: Montando uma transformação
Uma recomendação inicial é que cada transformação trate de apenas uma única dimensão ou tabela de fatos ou até mesmo para gerenciar variáveis. Desta maneira fica mais claro e facilitará depois na hora de montar os Jobs.
Neste tutorial serão abordadas apenas algumas maneiras de como é feita a extração, mas todas seguem um principio básico com as seguintes questões: Onde estão os dados?, O que fazer com os dados? e Onde inserir os dados?.
Selecionando uma nova extração o sistema abre uma nova área de trabalho e exibe um menu lateral com diversas opções. Neste basta procurar por Input > Table input (figura 4). Basta arrastar para a área de trabalho.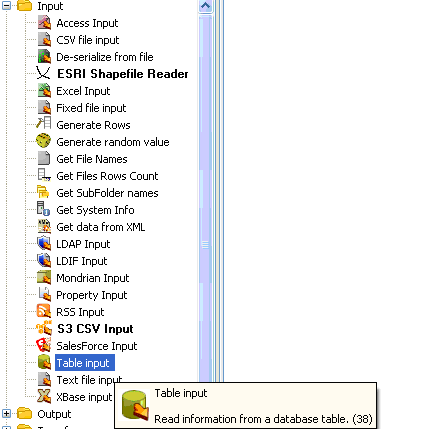
Figura 4 - Table Input
Com o ícone da tabela na tela da transformação, basta um duplo clique para editar o passo. A figura 5 exibe respectiva tela. Nesta deve-se informar, obrigatoriamente, a conexão, caso a mesma não exista pode ser criada clicando no botão new, neste caso a tela apresentada será a mesma da figura 2. Recomenda-se que se criem todas as conexões, previamente, para evitar retrabalho, uma vez que elas estarão disponíveis para todas as transformações.
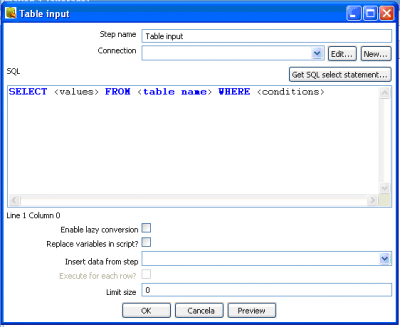
Figura 5 - Edição da consulta
Ainda na edição do sql existe uma grande liberdade do que se deseja retornar de dados. Diversas consultas podem ser realizadas, mas somente na base de dados especificada. Caso se necessário trabalhar com bases diferentes é recomendado criar um novo "Table input" e utilizar as funções de Joins oferecidas pelo Kettle.
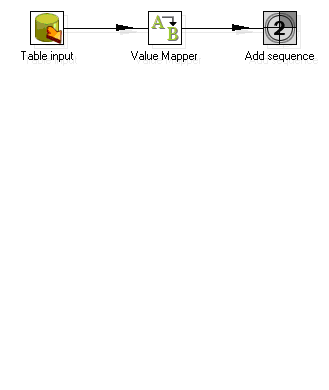
Figura 6 - Fluxo com mapeamento e geração de chave
O mapeamento é muito simples, basta informar qual coluna que será utilizada e em uma tabela abaixo informar o que deve ser modificado, pode também criar este mapeamento em uma nova coluna caso informe o nome da mesma. Já a criação da chave seqüencial pode utilizar variáveis definidas em uma outra transformação (para casos de dimensões de modificação lenta, ou seja, que sofre alterações e é necessário ter uma rotina de carga), para dimensões estáticas, basta colocar o valor inicial 1 e incrementar o que for necessário (figura 7).
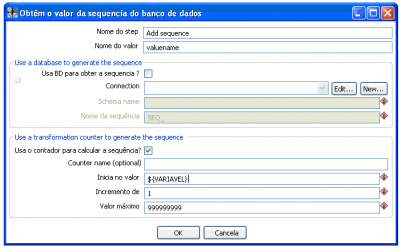
Figura 7 - Adicionando uma chave sequencial
Neste tutorial serão abordadas apenas algumas maneiras de como é feita a extração, mas todas seguem um principio básico com as seguintes questões: Onde estão os dados?, O que fazer com os dados? e Onde inserir os dados?.
Extração a partir de uma tabela
Neste ponto, geralmente o mais comum, a origem dos dados é de uma ou mais tabelas da base de dados dos sistemas transacionais.Selecionando uma nova extração o sistema abre uma nova área de trabalho e exibe um menu lateral com diversas opções. Neste basta procurar por Input > Table input (figura 4). Basta arrastar para a área de trabalho.

Figura 4 - Table Input
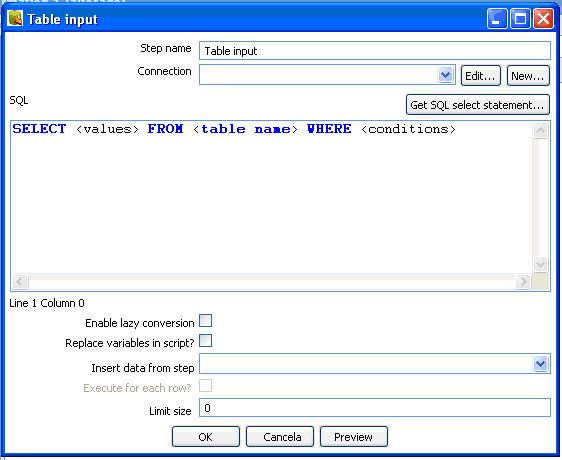
Figura 5 - Edição da consulta
Substituindo valores e adicionando uma chave
Funções muito comuns são a substituição de valores/mapeamento e a criação da chave sequencial da dimensão (figura 6).
Figura 6 - Fluxo com mapeamento e geração de chave
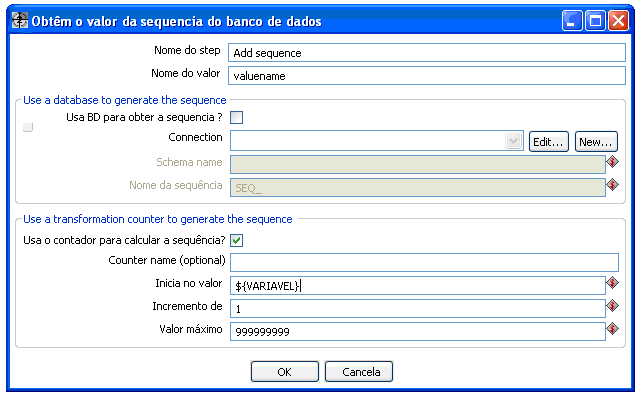
Figura 7 - Adicionando uma chave sequencial
Gostaria de parabenizá-lo pelo artigo. Parece ser uma ferramenta interessante, dado que para BI, conheço somente ferramentas pagas, não caras, mas pagas. Mas, como comentário, ficou faltando somente esclarecer um pouco mais, dado que é uma ferramenta de ETL, sobre as suas bases : Granularidade, Dimensões, Fatos... Bom, mas ficou muito bom.
Parabéns
Abraços