Tutorial Kettle
O Kettle é uma ferramenta para integração de dados, responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações, exportação de banco para arquivos, limpeza de dados e na integração de aplicações.

Parte 4: Utilizando variáveis e tratando strings
Utilizar variáveis em um projeto de ETL no Kettle é muito importante, elas facilitam e muito no controle da geração da chave incremental de uma dimensão de atualização lenta, dentre outras possibilidades.
Na figura 7 pode-se notar que o valor para iniciar a contagem está definido por ${VARIAVEL}, esta é uma nomenclatura padrão. O que é importante saber aqui é que as variáveis definidas em uma transformação, só podem ser utilizadas em outras transformações e não nela mesma.
Sendo assim deve-se criar uma transformação para iniciar estas variáveis (figura 8).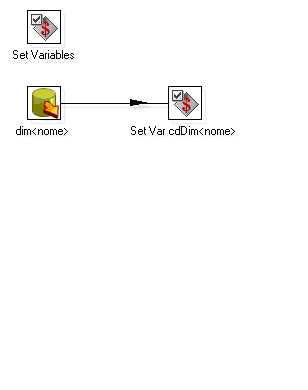
Figura 8 - Transformação setVariables
Utilizando a chave da dimensão como exemplo (${VARIAVEL} figura 7) deve-se criar uma consulta na dimensão onde será verificada o maior valor da chave (Table input figura 8), o código está exemplificado abaixo. Após isso, tem que estabelecer uma ligação com o passo de criação de variáveis. Neste exemplo foi denominada: VARIAVEL. Editando a variável pode-se definir qual a visibilidade da mesma, por default utiliza-se "Valid in the root job" (figura 9).
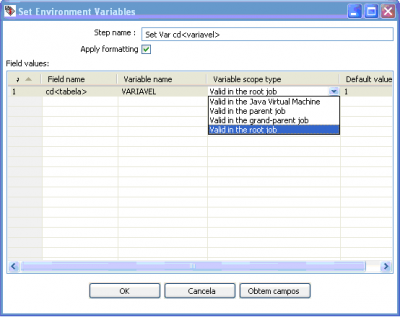
Figura 9 - Configurando uma variável
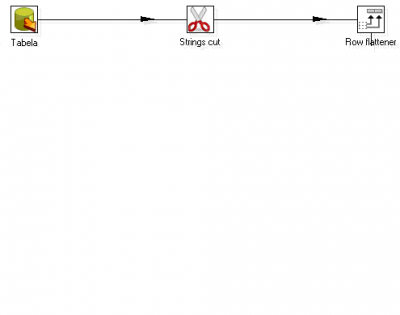
Figura 10 - Transformação de dados
Também na figura 10 podemos identificar um passo chamado "Row flattener". Que em linhas gerais, e até pelo próprio desenho, coloca n valores consecutivos de uma coluna em n colunas em uma mesma linha. De acordo com a figura 11, a coluna chSinalizacao vai ser transformada em 3 colunas na mesma linha.
Assim para cada 3 linhas consecutivas na entrada a saída será uma única linha com 3 novas colunas, esta operação ocorre até que todas as linhas da entrada sejam percorridas. Vale lembrar que está é uma situação específica e depende da ordenação dos dados de entrada, caso contrário poderá produzir um registro com dados inconsistentes.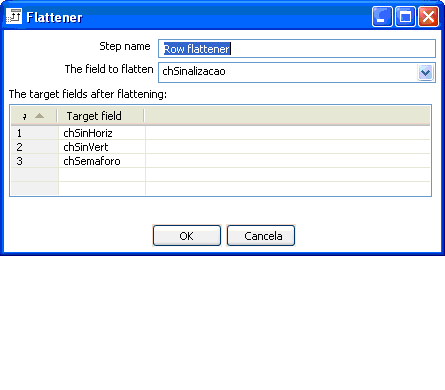
Figura 11 - Row flattener
Na figura 7 pode-se notar que o valor para iniciar a contagem está definido por ${VARIAVEL}, esta é uma nomenclatura padrão. O que é importante saber aqui é que as variáveis definidas em uma transformação, só podem ser utilizadas em outras transformações e não nela mesma.
Sendo assim deve-se criar uma transformação para iniciar estas variáveis (figura 8).

Figura 8 - Transformação setVariables

Figura 9 - Configurando uma variável
Tratando string e colocando valores de uma coluna em uma linha
Por algumas vezes ou por alguma característica que queremos isolar, existe a necessidade de trabalhar com partes de uma string. No Kettle isso é possível ser feito com o uso da função "Strings cut" (figura 10). Basicamente ao editar este passo basta informar os campos que necessitam de edição e informar ponto de inicio e fim para o corte. Esta ação pode sobrescrever o campo ou, caso seja necessário, poderá ser escrito em um novo campo definido pelo usuário.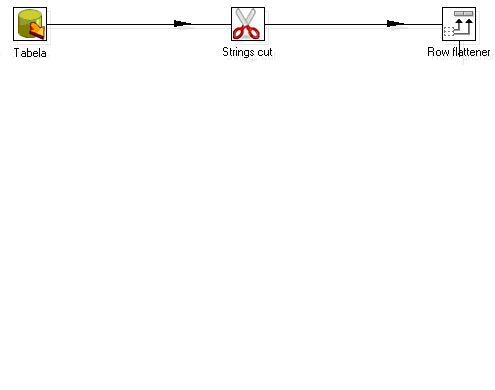
Figura 10 - Transformação de dados
Assim para cada 3 linhas consecutivas na entrada a saída será uma única linha com 3 novas colunas, esta operação ocorre até que todas as linhas da entrada sejam percorridas. Vale lembrar que está é uma situação específica e depende da ordenação dos dados de entrada, caso contrário poderá produzir um registro com dados inconsistentes.

Figura 11 - Row flattener
Gostaria de parabenizá-lo pelo artigo. Parece ser uma ferramenta interessante, dado que para BI, conheço somente ferramentas pagas, não caras, mas pagas. Mas, como comentário, ficou faltando somente esclarecer um pouco mais, dado que é uma ferramenta de ETL, sobre as suas bases : Granularidade, Dimensões, Fatos... Bom, mas ficou muito bom.
Parabéns
Abraços